在流水线中使用缓存¶
CI 中经常使用流水线执行编译、构建等工作,现代语言中,无论是 Java、NodeJS、Python 还是 Go, 都需要下载依赖包来执行构建工作。这一过程往往需要占用大量网络资源,会拖慢流水线构建速度,成为 CI/CD 中的瓶颈,降低我们的生产效率。
类似的,还包括语法检查产生的缓存文件,Sonarqube 扫描代码生成的缓存文件,如果每次都重新开始运行,将无法有效利用工具本身的缓存机制。
应用工作台本身提供了基于 K8S 的 hostPathVolume 的缓存机制,利用节点本地路径可以缓存例如 /root/.m2、/home/jenkins/go/pkg、/root/.cache/pip 等包默认路径。
但是在 DCE 5.0 多租户的场景下,更多用户希望保持缓存的隔离,避免侵入和冲突。这里介绍一种基于 Jenkins 插件 Job Cacher 实现的一种缓存机制。
通过 Job Cacher,我们可以使用 AWS S3 或者 S3 接口兼容的存储系统(例如 MinIO)来实现流水线级别的缓存隔离。
准备工作¶
-
提供一个 S3 或类 S3 的存储后端,可以参考创建 MinIO 实例 - DaoCloud Enterprise 在 DCE 5.0 上创建一个 MinIO,并创建一个 bucket,准备好
access key和secret。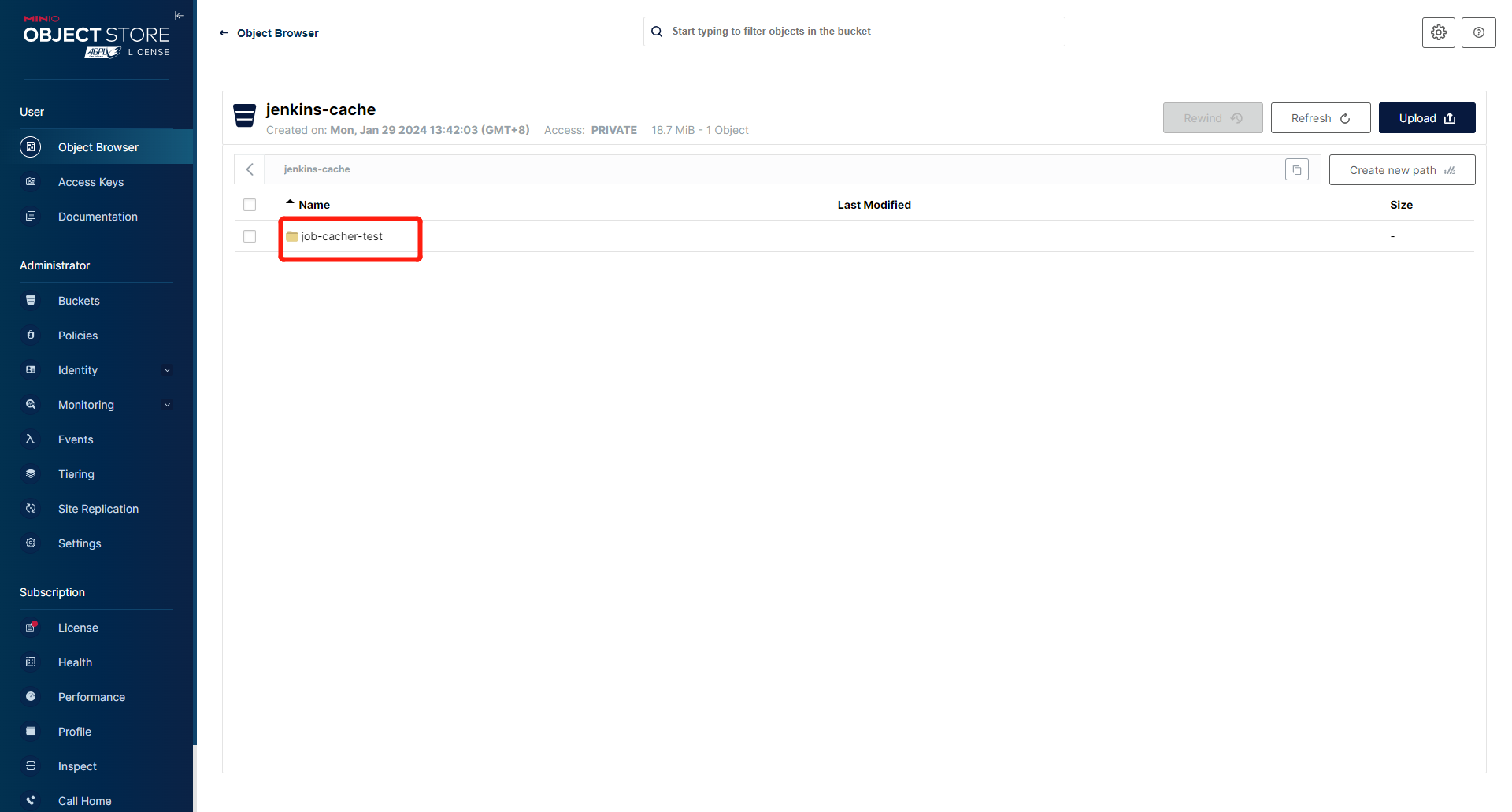
-
在 Jenkins 的 系统管理 -> 插件管理 界面下,安装插件 job-cacher:
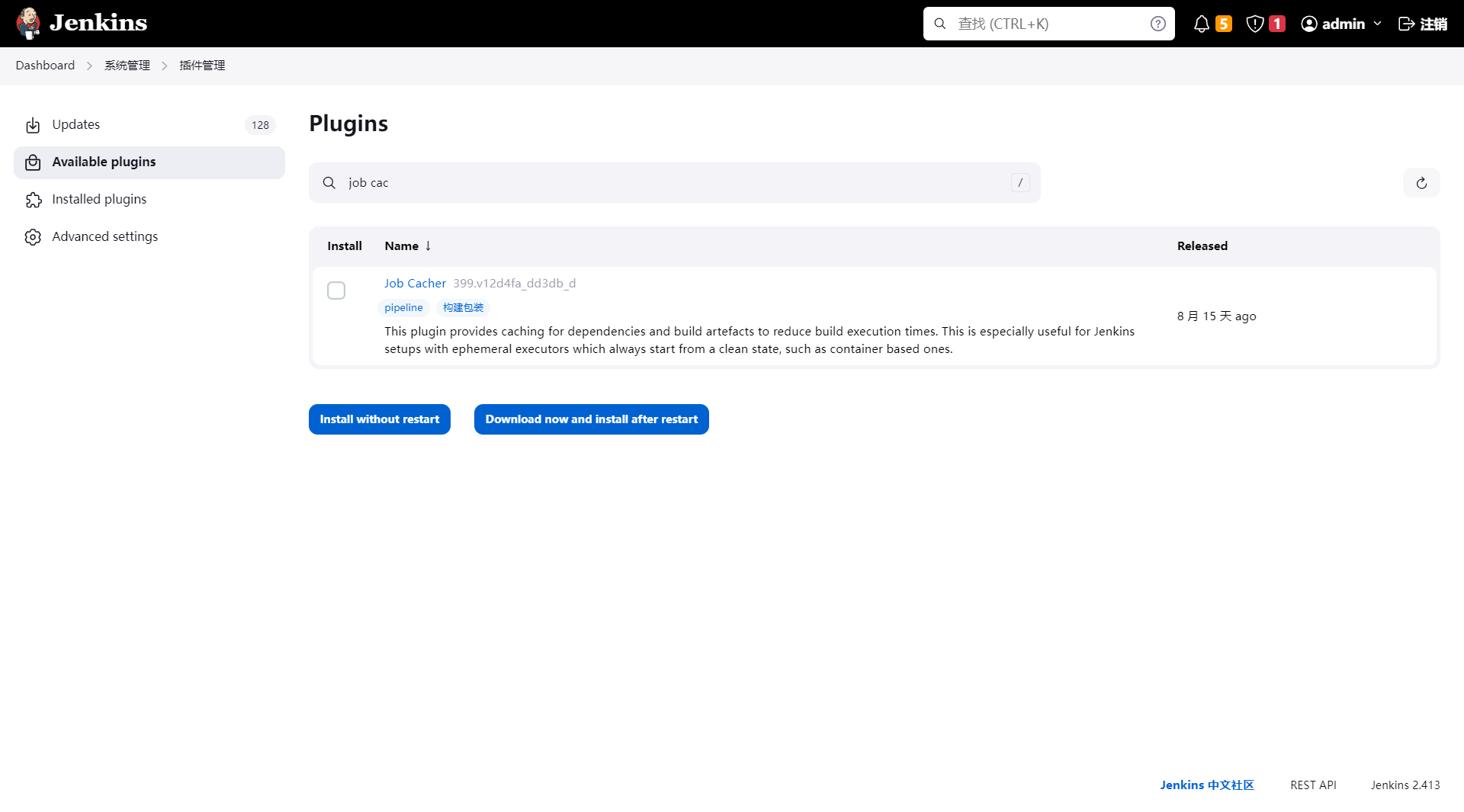
-
如果要使用 S3 的存储,还需要安装插件如下:
- groupId: org.jenkins-ci.plugins artifactId: aws-credentials source: version: 218.v1b_e9466ec5da_ - groupId: org.jenkins-ci.plugins.aws-java-sdk artifactId: aws-java-sdk-minimal # aws-crendetials依赖 source: version: 1.12.633-430.vf9a_e567a_244f - groupId: org.jenkins-ci.plugins artifactId: jackson2-api # 被其他插件依赖 source: version: 2.16.1-373.ve709c6871598
Note
Amamba 提供的v0.3.2及之前的Helm Chart 对应的 Jenkins 版本为2.414,经测试这个版本的 Job Cacher 399.v12d4fa_dd3db_d 不能正确的识别 S3 配置,请注意使用升级后的 Jenkins 及 Job Cacher。
配置¶
在 系统管理 界面,如下配置 S3 的参数:
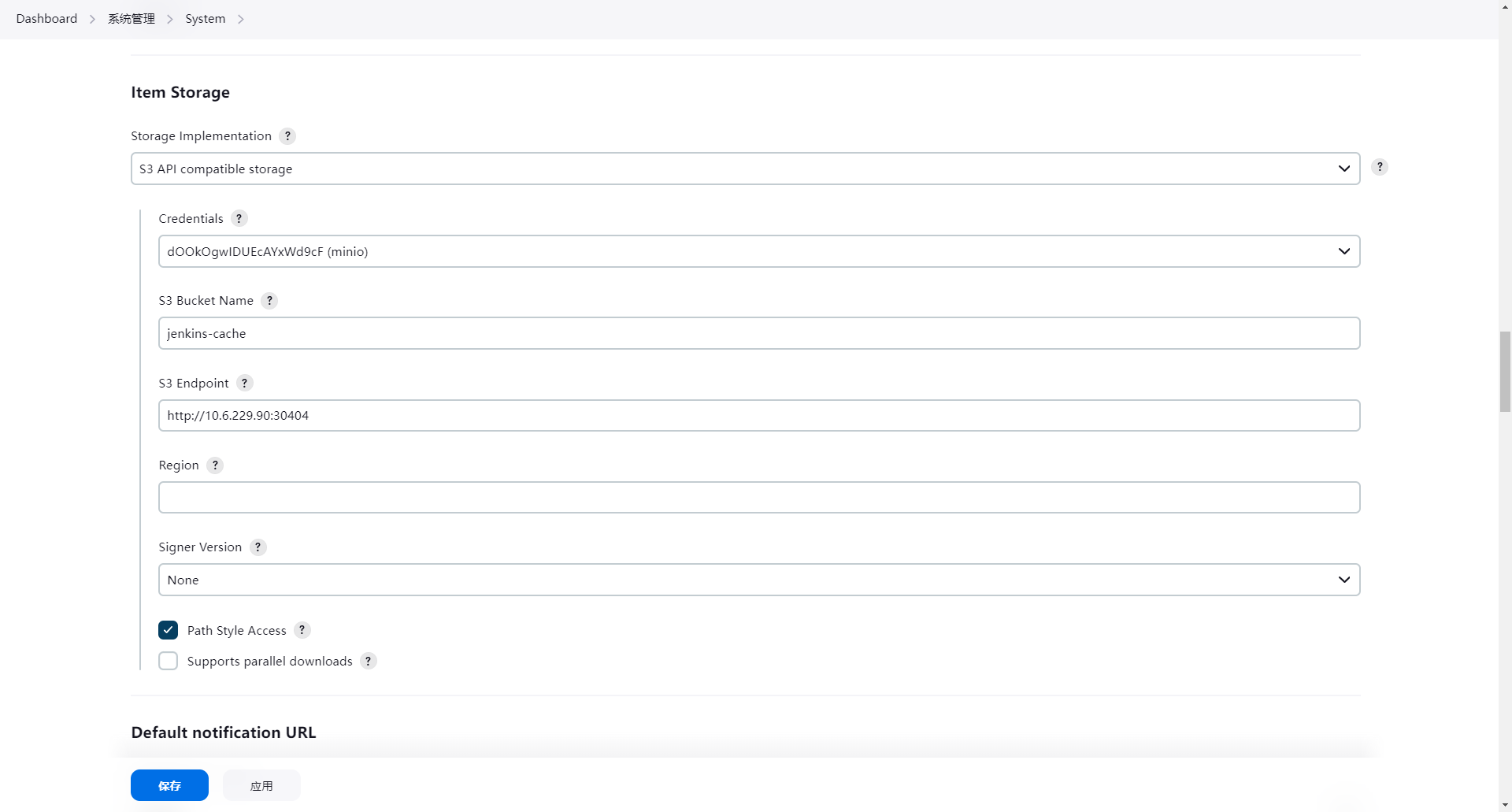
或者可以通过 CasC 的方式修改 ConfigMap,以持久化配置。
修正后的 YAML 示例如下:
unclassified:
...
globalItemStorage:
storage:
nonAWSS3:
bucketName: jenkins-cache
credentialsId: dOOkOgwIDUEcAYxWd9cF
endpoint: http://10.6.229.90:30404
region: Auto
signerVersion:
parallelDownloads: true
pathStyleAccess: false
使用¶
完成上述配置后,我们就可以在 Jenkinsfile 中使用 Job Cacher 提供的函数 cache 了,以如下的流水线为例:
pipeline {
agent {
node {
label 'nodejs'
}
}
stages {
stage('clone') {
steps {
git(url: 'https://gitlab.daocloud.cn/ndx/engineering/application/amamba-test-resource.git', branch: 'main', credentialsId: 'git-amamba-test')
}
}
stage('test') {
steps {
sh 'git rev-parse HEAD > .cache'
cache(caches: [
arbitraryFileCache(
path: "pipeline-template/nodejs/node_modules",
includes: "**/*",
cacheValidityDecidingFile: ".cache",
)
]){
sh 'cd pipeline-template/nodejs/ && npm install && npm run build && npm install jest jest-junit && npx jest --reporters=default --reporters=jest-junit'
junit 'pipeline-template/nodejs/junit.xml'
}
}
}
}
}
该流水线定义了两个阶段 clone 和 test,在 test 阶段,我们通过对 node_modules 下的所有文件进行缓存, 避免每次都要拉取 npm 包。同时,我们定义了 .cache 文件作为缓存的唯一性标识, 也就是说当前分支一旦有任何更新缓存将会失效,并重新拉取 npm 包。
完成之后可以看到,第二次重复运行流水线,时间大大缩短:
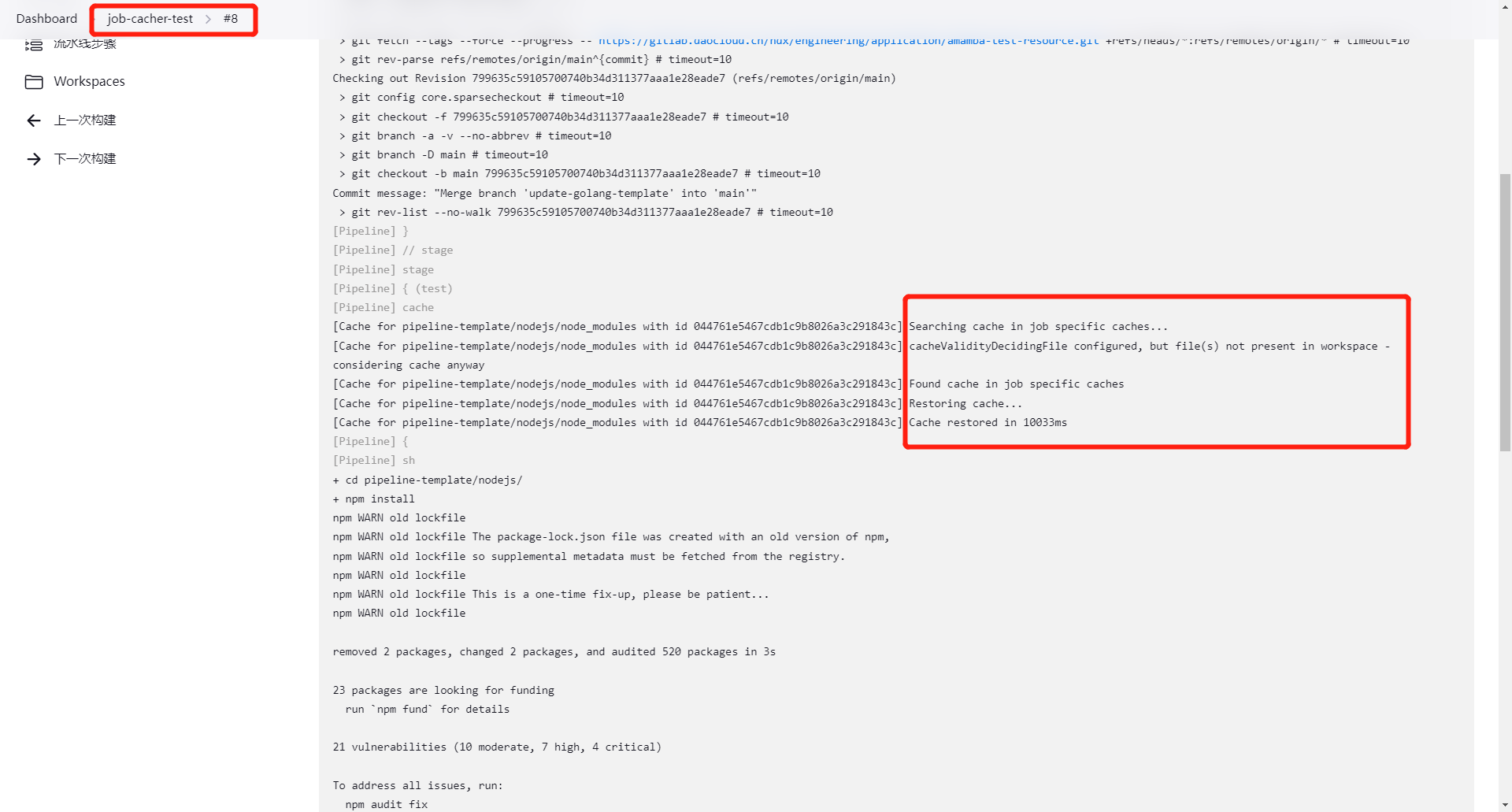
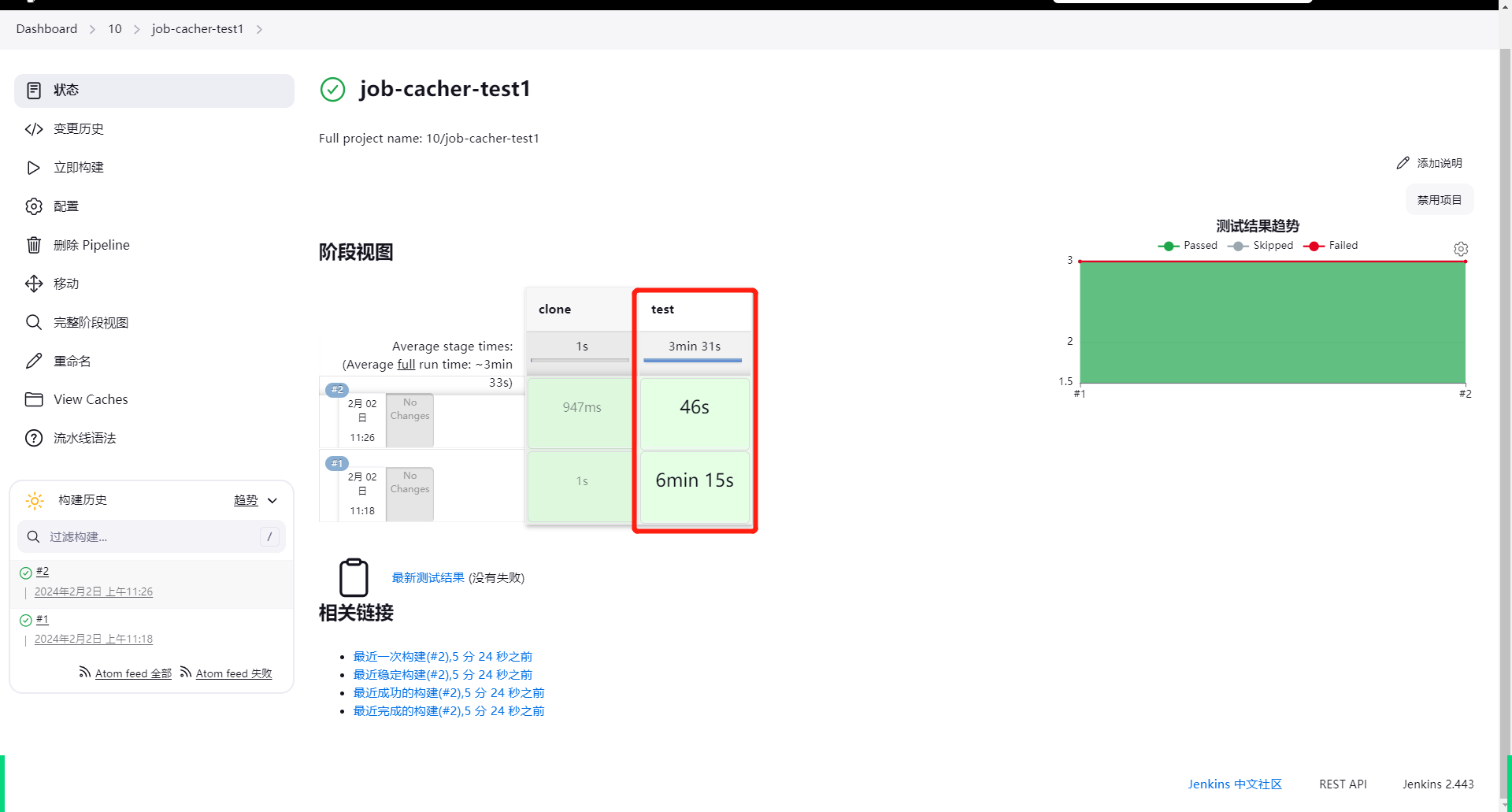
更多的选项可以参考文档:Job Cacher | Jenkins plugin
其他¶
- 关于性能 :job-cacher 也是基于
MasterToSlaveFileCallable实现的,是基于远程调用在 agent 中直接上传和下载的,而不是 agent -> controller -> S3 的方式; - 关于缓存大小 :job-cacher 支持多种压缩算法,包括
ZIP、TARGZ、TARGZ_BEST_SPEED、TAR_ZSTD、TAR,默认是使用TARGZ; - 关于缓存清理 :job-cacher 支持按流水线设置
maxCacheSize。