Cilium implements socket acceleration based on eBPF¶
Original author: tanberBro

With the continuous development of cloud native, more and more applications are deployed on the cloud. Some of these applications have very strict real-time requirements, which makes us have to improve the performance of these applications to achieve faster service speed.
Scenes¶
In order to achieve faster service speed, a scenario is: when two applications calling each other are deployed on the same node, each request and return needs to go through the socket layer, TCP/IP protocol stack, data link layer, physical layer. If the request and return bypass the TCP/IP protocol stack and directly redirect the data packet to the peer socket at the socket layer, it will greatly reduce the time spent on sending the data packet, thereby speeding up the service. Based on this idea, eBPF technology stores socket information through mapping, and uses helper functions to realize the ability to redirect data packets to the peer socket layer. Based on the capability of eBPF, Cilium realizes the socket layer acceleration effect.
Architecture¶
The overall structure of Cilium is as follows:
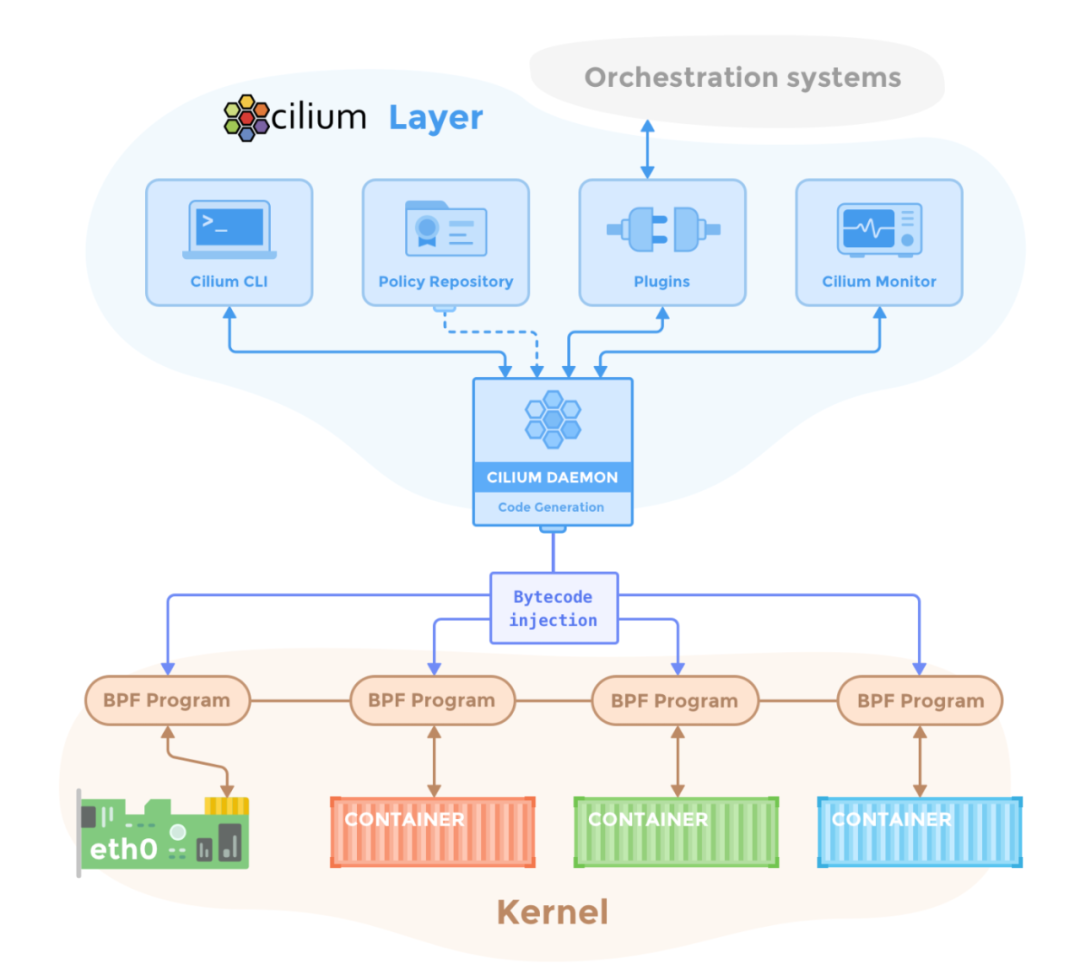
Cilium implements socket layer acceleration in the daemon component, and the daemon component will start a Pod on each node in the cluster, so the socket acceleration effect will be applied to each node.
Capabilities Overview¶
When Cilium handles that the source end and the target end are on the same node, it can redirect the traffic directly to the target end socket at the socket layer, which directly bypasses the entire TCP/IP protocol stack, thereby achieving the effect of acceleration, as shown in the figure below Show.
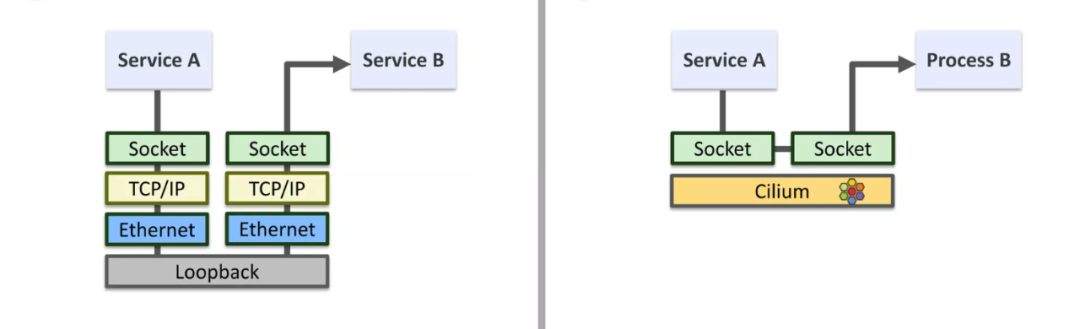
Implementation principle¶
Principle overview¶
Cilium achieves the above capabilities using the following eBPF programs and maps:
- The eBPF map contains:
- Cilium_sock_ops (type: BPF_MAP_TYPE_SOCKHASH): store socket information.
- eBPF program contains:
- obpf_sockmap (type: BPF_PROG_TYPE_SOCK_OPS): Intercept the socket connection establishment operation in the system, and store the socket information in cilium_sock_ops.
- obpf_redir_proxy (type: BPF_PROG_TYPE_SK_MSG): intercept the sendmsg system call in the system, extract the key, and redirect the data directly to the peer socket.
bpf_sockmap needs to be attached to the cgroup, and will be attached to /run/cilium/cgroupv2 in Cilium, so bpf_sockmap can be applied to all processes belonging to the cgroup in the system.
Code¶
The following code is based on the cilium/cilium v1.13 branch. Cilium uses C language to write eBPF code, and compiles, loads and attaches eBPF code through go language.
eBPF mapping¶
cilium_sock_ops: This mapping uses sock_key as the key, and sock_key stores source IP, destination IP, protocol, source port, and destination port, that is, socket quintuple.
bpf/sockops/bpf_sockops.h
struct sock_key {
union {
struct {
__u32 sip4;
__u32 pad1;
__u32 pad2;
__u32 pad3;
};
union v6addr sip6;
};
union {
struct {
__u32 dip4;
__u32 pad4;
__u32 pad5;
__u32 pad6;
};
union v6addr dip6;
};
__u8 family;
__u8 pad7;
__u16 pad8;
__u32 sport;
__u32 dport;
} __packed;
struct {
__uint(type, BPF_MAP_TYPE_SOCKHASH);
__type(key, struct sock_key);
__type(value, int);
__uint(pinning, LIBBPF_PIN_BY_NAME);
__uint(max_entries, SOCKOPS_MAP_SIZE);
} SOCK_OPS_MAP __section_maps_btf;
eBPF programs¶
bpf_sockmap: The BPF_PROG_TYPE_SOCK_OPS type of program is different from other types of programs. It will be executed in multiple places. The parameter skops->op can get the place where the current program is executed. Here, when the active and passive connection establishment is completed, and the protocol family is AF_INET6 (TCP/IPv6), AF_INET (TCP/IPv4), it will enter bpf_sock_ops_ipv4 processing socket. bpf_sock_ops_ipv6 will judge that the target IPV4 is not empty, and will enter bpf_sock_ops_ipv4 for further processing.
bpf/sockops/bpf_sockops.c
__section("sockops")
int cil_sockops(struct bpf_sock_ops *skops)
{
__u32 family, op;
family = skops->family;
op = skops->op;
switch(op) {
case BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB:
case BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB:
#ifdef ENABLE_IPV6
if (family == AF_INET6)
bpf_sock_ops_ipv6(skops);
#endif
#ifdef ENABLE_IPV4
if (family == AF_INET)
bpf_sock_ops_ipv4(skops);
#endif
break;
default:
break;
}
return 0;
}
bpf_sock_ops_ipv4: here first call sk_extract4_key to extract the key, which is the key of cilium_sock_ops; call sk_lb4_key to extract lb4_key, Call lb4_lookup_service, query mapping according to lb4_key: cilium_lb4_services_v2 to get L4 load information, if found, it means the target is L4 load address, Return directly, end the call, and use the L4/L3 protocol stack to process downward; call lookup_ip4_remote_endpoint to query the mapping according to the target IP: cilium_ipcache, The mapping stores the correspondence between all network information and identity information, finds the identity ID of the target IP; calls policy_sk_egress for policy decision; Call redirect_to_proxy to determine whether to redirect to the proxy (verdict > 0), if so, replace the source IP and source port of the key with the address of the proxy, Call the bpf helper function bpf_sock_hash_update to store the key in cilium_sock_ops; if not, call __lookup_ip4_endpoint, Query the mapping according to the target IP: cilium_lxc, which stores all local Pod information and host information, If found, it means internal access of the machine, call the bpf helper function bpf_sock_hash_update to store the key in cilium_sock_ops.
bpf/sockops/bpf_sockops.c
static inline void bpf_sock_ops_ipv4(struct bpf_sock_ops *skops)
{
struct lb4_key lb4_key = {};
__u32 dip4, dport, dst_id = 0;
struct endpoint_info *exists;
struct lb4_service *svc;
struct sock_key key = {};
int verdict;
sk_extract4_key(skops, &key);
/* If endpoint a service use L4/L3 stack for now. These can be
* pulled in as needed.
*/
sk_lb4_key(&lb4_key, &key);
svc = lb4_lookup_service(&lb4_key, true, true);
if (svc)
return;
/* Policy lookup required to learn proxy port */
if (1) {
struct remote_endpoint_info *info;
info = lookup_ip4_remote_endpoint(key.dip4);
if (info != NULL && info->sec_label)
dst_id = info->sec_label;
else
dst_id = WORLD_ID;
}
verdict = policy_sk_egress(dst_id, key.sip4, (__u16)key.dport);
if (redirect_to_proxy(verdict)) {
__be32 host_ip = IPV4_GATEWAY;
key.dip4 = key.sip4;
key.dport = key.sport;
key.sip4 = host_ip;
key.sport = verdict;
sock_hash_update(skops, &SOCK_OPS_MAP, &key, BPF_NOEXIST);
return;
}
/* Lookup IPv4 address, this will return a match if:
* - The destination IP address belongs to the local endpoint manage
* by Cilium.
* - The destination IP address isan IP address associated with the
* host itself.
* Then because these are local IPs that have passed LB/Policy/NAT
* blocks redirect directly to socket.
*/
exists = __lookup_ip4_endpoint(key.dip4);
if (!exists)
return;
dip4 = key.dip4;
dport = key.dport;
key.dip4 = key.sip4;
key.dport = key.sport;
key.sip4 = dip4;
key.sport = dport;
sock_hash_update(skops, &SOCK_OPS_MAP, &key, BPF_NOEXIST);
}
bpf_redir_proxy: BPF_PROG_TYPE_SK_MSG type program will be executed when calling sendmsg on the socket, here is to run bpf_redir_proxy. The program first calls sk_extract4_key to extract the key, which is the key of cilium_sock_ops; calls lookup_ip4_remote_endpoint Query the mapping according to the target IP: cilium_ipcache, which stores the correspondence between all network information and identity information, and finds the identity ID of the target IP; Call policy_sk_egress for policy ruling; if the ruling is passed, call the bpf helper function bpf_msg_redirect_hash, This function maps cilium_sock_ops through the incoming key query to obtain the peer socket information, and then redirects the message to the ingress direction of the peer socket to complete the redirection of the socket layer.
bpf/sockops/bpf_redir.c
__section("sk_msg")
int cil_redir_proxy(struct sk_msg_md *msg)
{
struct remote_endpoint_info *info;
__u64 flags = BPF_F_INGRESS;
struct sock_key key = {};
__u32 dst_id = 0;
int verdict;
sk_msg_extract4_key(msg, &key);
/* Currently, pulling dstIP out of endpoint
* tables. This can be simplified by caching this information with the
* socket to avoid extra overhead. This would require the agent though
* to flush the sock ops map on policy changes.
*/
info = lookup_ip4_remote_endpoint(key.dip4);
if (info != NULL && info->sec_label)
dst_id = info->sec_label;
else
dst_id = WORLD_ID;
verdict = policy_sk_egress(dst_id, key.sip4, (__u16)key.dport);
if (verdict >= 0)
msg_redirect_hash(msg, &SOCK_OPS_MAP, &key, flags);
return SK_PASS;
}
compile, load and attach eBPF programs¶
Cilium uses go language and calls external commands clang llc bpftool to compile, load and attach.
When Cilium configures sockops-enable: "true" and the kernel supports BPF Sock ops, Compile, load and attach are performed when the daemon is started and the init operation is performed. The code is as follows:
daemon/cmd/daemon.go
…
if option.Config.SockopsEnable {
eppolicymap. CreateEPPolicyMap()
if err := sockops. SockmapEnable(); err != nil {
return fmt.Errorf("failed to enable Sockmap: %w", err)
} else if err := sockops. SkmsgEnable(); err != nil {
return fmt.Errorf("failed to enable Sockmsg: %w", err)
} else {
sockmap. SockmapCreate()
}
}
…
sockops.SockmapEnable: first call clang... | llc ... to compile bpf_sockops.c into bpf_sockops.o; Then load bpf_sockops.o into the kernel, after loading bpf_sockops.o will pin to /sys/fs/bpf/bpf_sockops (default), Then call bpftool cgroup attach... to attach /sys/fs/bpf/bpf_sockops to /run/cilium/cgroupv2 (default) cgroup, Finally pin cilium_sock_ops to /sys/fs/bpf/tc/globals/cilium_sock_ops.
pkg/sockops/sockops.go
func SockmapEnable() error {
err := bpfCompileProg(cSockops, oSockops)
if err != nil {
return err
}
progID, mapID, err := bpfLoadAttachProg(oSockops, eSockops, sockMap)
if err != nil {
return err
}
log.Infof("Sockmap Enabled: bpf_sockops prog_id %d and map_id %d loaded", progID, mapID)
return nil
}
sockops.SkmsgEnable: first call clang... | llc ... to compile bpf_redir.c into bpf_redir.o; Then load bpf_redir.o into the kernel, after loading bpf_redir.o will pin to /sys/fs/bpf/bpf_redir (default), Call bpftool prog show pinned against bpf_redir... to get the bpf_redir program ID, call bpftool map show Obtain the mapping ID used by bpf_sockops, and finally call bpftool prog attach... to attach bpf_redir to cilium_sock_ops according to the program ID and mapping ID.
pkg/sockops/sockops.go
func SkmsgEnable() error {
err := bpfCompileProg(cIPC, oIPC)
if err != nil {
return err
}
err = bpfLoadMapProg(oIPC, eIPC)
if err != nil {
return err
}
log.Info("Sockmsg Enabled, bpf_redir loaded")
return nil
}
Summary¶
To sum up, use cilium_sock_ops mapping as socket information storage carrier, intercept and store socket information through bpf_sockmap program, Call bpf_msg_redirect_hash through bpf_redir_proxy to implement socket redirection. Through the Cilium daemon component, Load the eBPF program and map into the kernel, and attach it to /run/cilium/cgroupv2 to accelerate socket communication on the same node, Since the scope of acceleration is based on the sockets on all hosts monitored by the cgroup, as long as the communication between sockets on the same node can be accelerated.
Acceleration effect¶
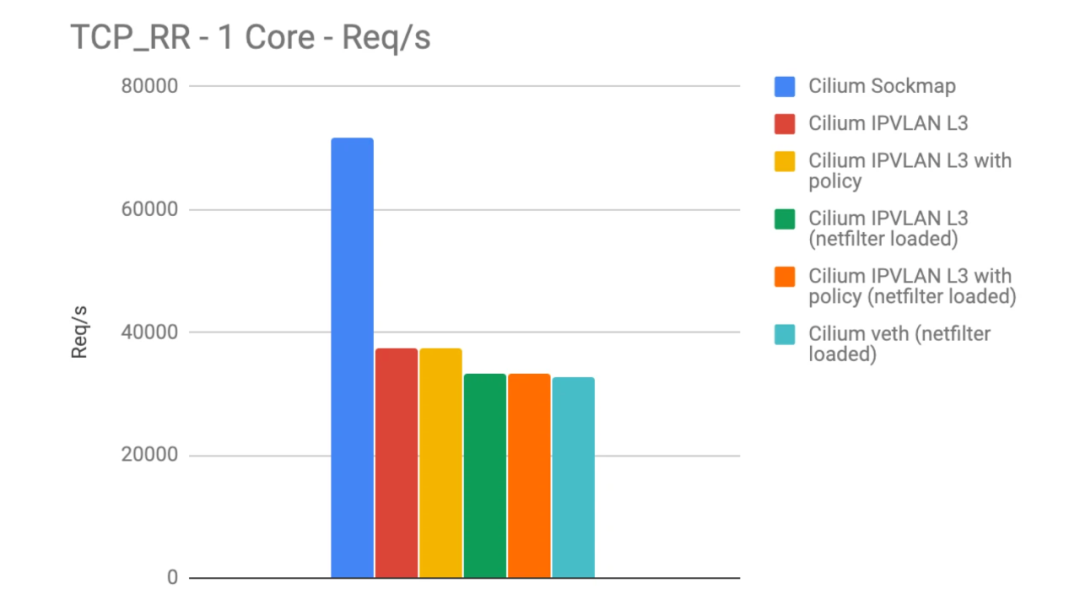
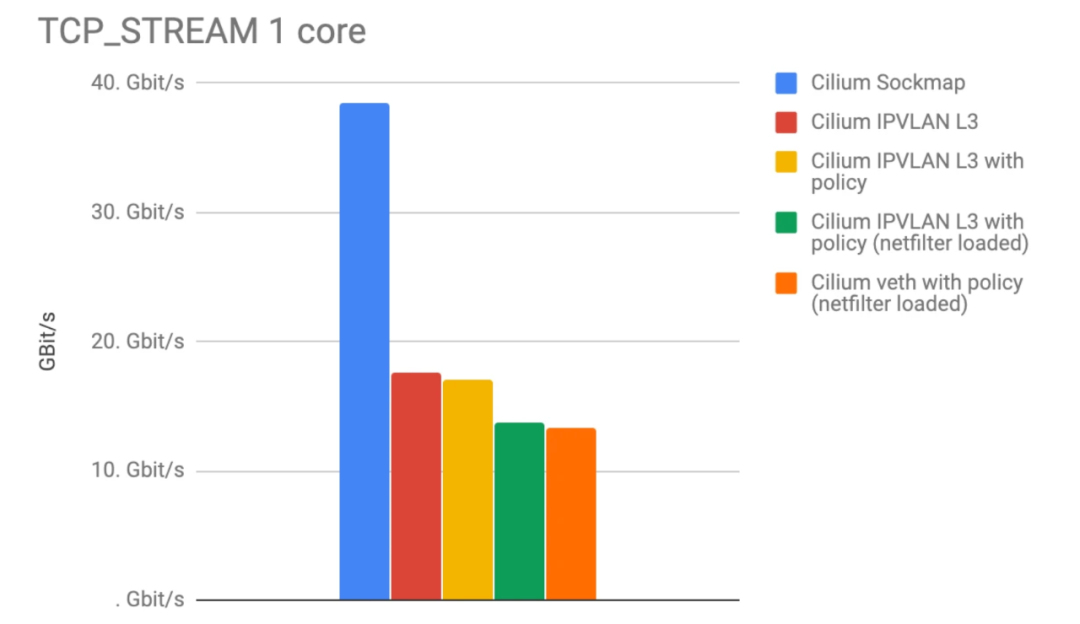
As shown in the figure above, after using eBPF socket acceleration (blue), the number of requests/s and throughput are doubled.
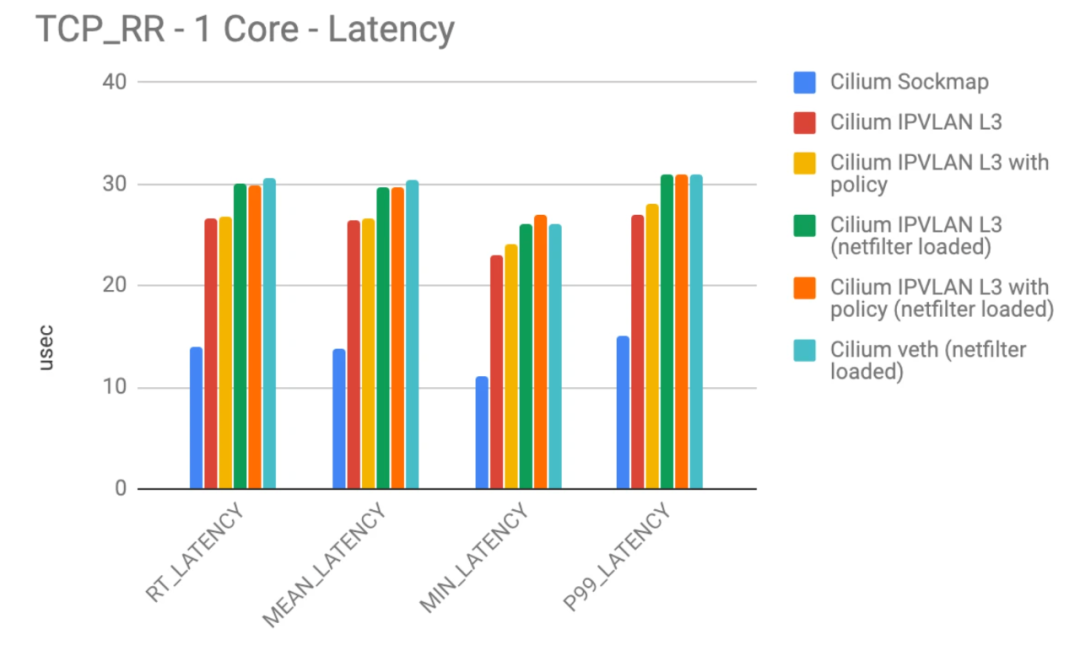
As shown in the figure above, the eBPF socket acceleration (blue) is compared with the delay of the TCP/IP stack, and the performance of the eBPF socket acceleration is better than that of the conventional TCP/IP stack.
Next, let's look at the comparison of acceleration effects when sending and receiving messages of various lengths, and analyze the acceleration principle in depth:
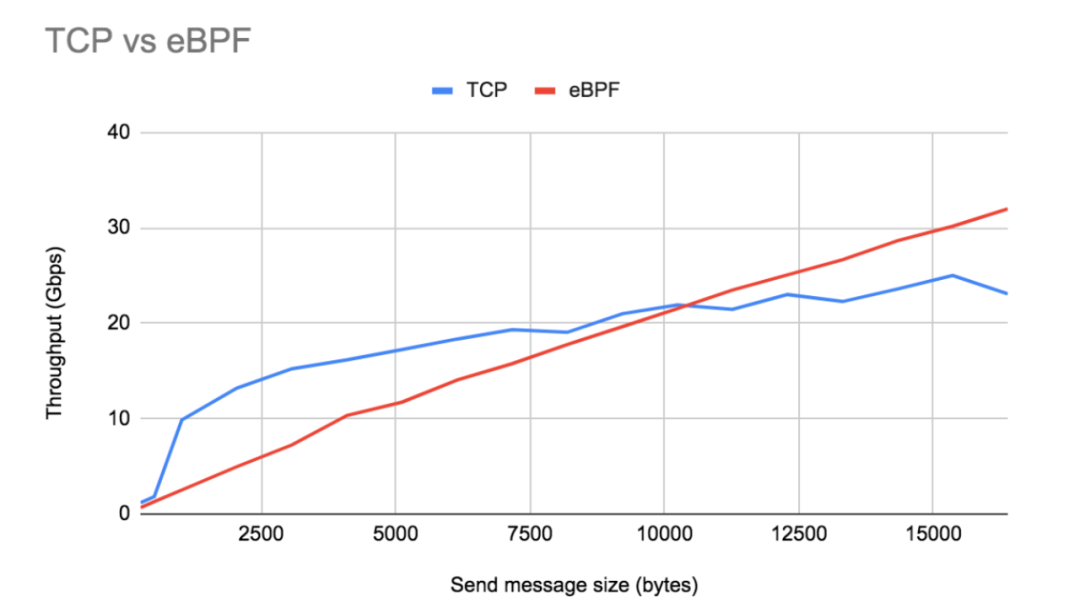
As shown in the figure above, after using the eBPF socket to accelerate, the throughput and the size of the sent message are linear. This is because when an application sends a large message, the There is almost no additional overhead, but when sending small messages, using the TCP/IP protocol stack, the throughput will be greater than the throughput after eBPF socket acceleration, This is because the Nagle algorithm is enabled by default in the TCP/IP stack. Nagle's algorithm is used to solve the problem of congestion caused by the flooding of small packets in a slow network. In this algorithm, as long as there is a TCP segment that is not confirmed when it is smaller than the size of the TCP MSS, the batch transmission data operation will be performed. This batching results in more data being transferred at a time and amortizes the overhead, so it can exceed the throughput after eBPF socket acceleration. But as the sent message gets bigger and bigger, Beyond MSS, the TCP/IP stack loses its batch processing advantage, and at these large packet send sizes, eBPF socket acceleration far exceeds the throughput of a Nagle algorithm-enabled TCP/IP stack with its low overhead.
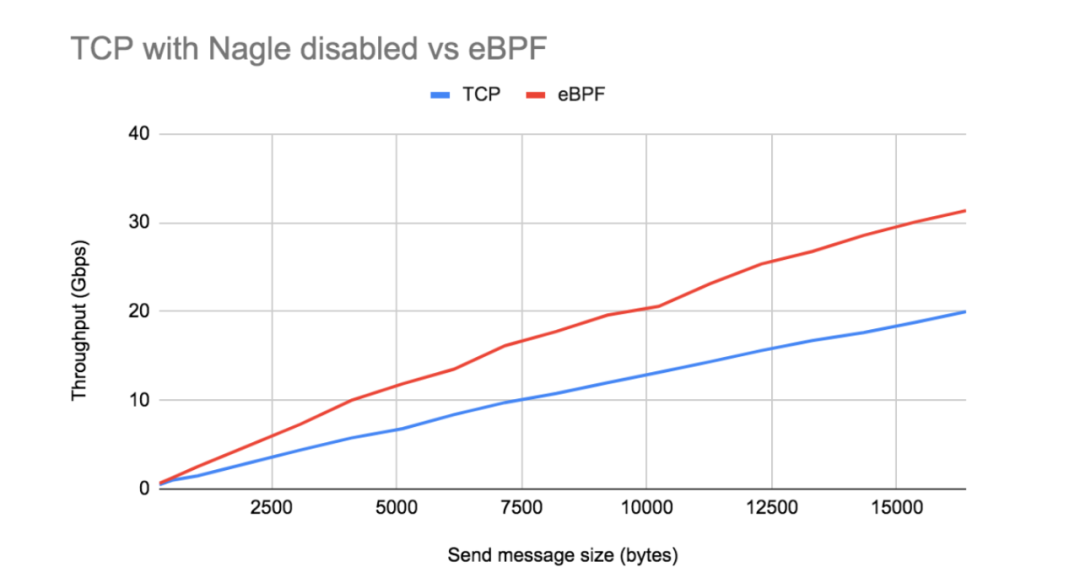
As the graph above shows, with Nagle's algorithm disabled, the throughput gain of regular TCP compared to eBPF socket speedup completely disappears. The performance of TCP/IP stack and eBPF socket acceleration increases linearly as expected, since the cost overhead of each send call of eBPF is fixed, So eBPF has a bigger slope than regular TCP/IP. For larger send message sizes and smallerFor TCP MSS, this performance gap is even more pronounced.
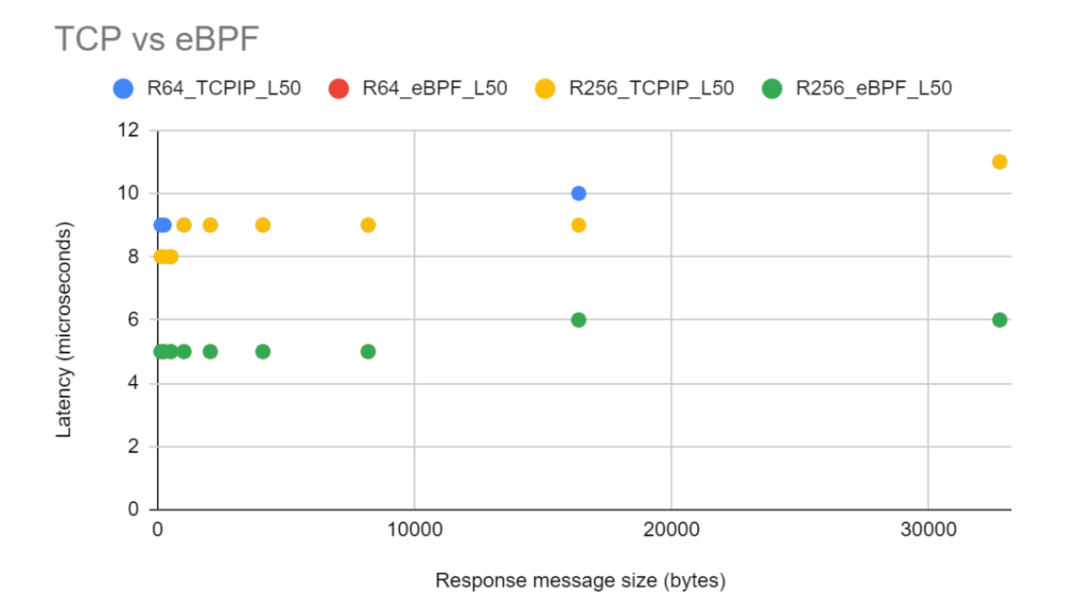
As shown in the figure above, the eBPF socket acceleration is compared with the TCP/IP stack delay, and the eBPF socket acceleration is better than the conventional TCP/IP stack. Performance is nearly 50% better than regular TCP/IP stacks. In contrast to the TCP/IP stack, eBPF works by redirecting packets from the source socket's transmit queue to the destination socket's receive queue, Thereby eliminating any protocol-level overhead (slow start, congestion avoidance, flow control, etc.). Also, the size of the request message size has no effect on latency.
References¶
- Welcome to Cilium's documentation!
- How to use eBPF for accelerating Cloud Native applications
- Lessons from using eBPF (and bypassing TCP/IP) for accelerating Cloud Native applications
- Accelerating Envoy and Istio with Cilium and the Linux Kernel
- Congestion Control in IP/TCP Internetworks
- Cilium 1.4: Multicluster Service Routing, DNS Authorization, IPVLAN support, Transparent Encryption, Flannel Integration, Benchmarking other CNIs