High Availability Deployment Across Data Centers¶
Scenario Requirements¶
The customer's data center environment consists of a single Kubernetes (k8s) cluster spanning Data Center A and Data Center B. They want to deploy a 3-master 3-slave Redis cluster to achieve high availability across the data centers. They expect Redis to continue providing services even when one data center is offline.
Solution¶
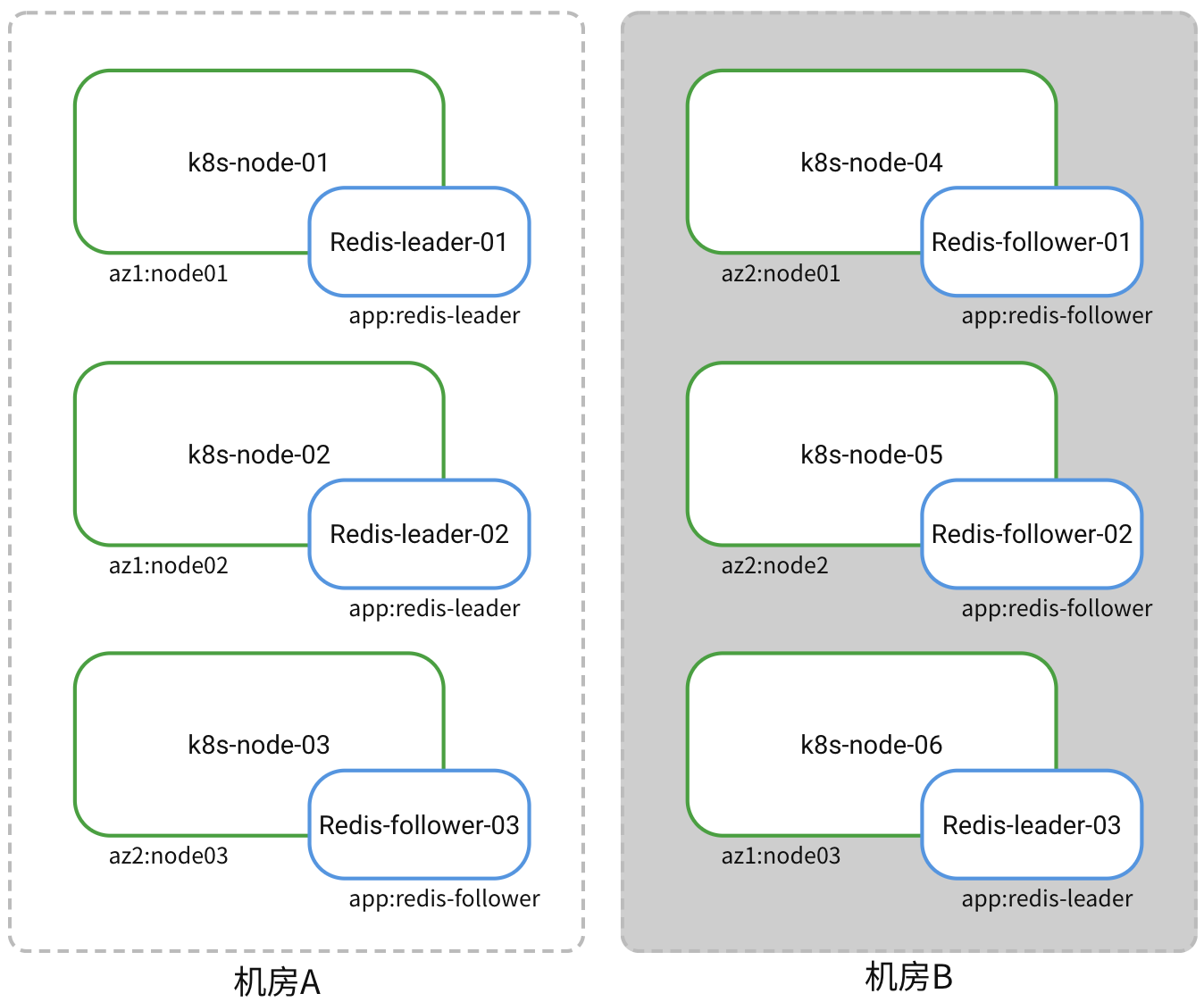
To meet the high availability requirements across the two data centers, the Redis replicas need to be deployed in the following manner:
- 3 leader replicas running on cluster nodes: k8s-node-01, k8s-node-02, k8s-node-06
- 3 follower replicas running on cluster nodes: k8s-node-03, k8s-node-04, k8s-node-05
- Ensure that each cluster node runs only one Redis replica
This solution uses workload scheduling strategies to achieve the deployment goals through weighted node affinity and workload anti-affinity policies.
Note
Please ensure that each node has sufficient resources to avoid scheduler failure due to resource shortage.
1. Label Configuration¶
Redis Workload Labels¶
To schedule the leader and follower replicas separately, the Redis replicas are divided using labels:
| Redis Replica | Label |
|---|---|
| redis-leader | app:redis-leader |
| redis-follower | app:redis-follower |
Cluster Node Labels¶
To allocate the leader and follower replicas to two different data centers, two topological domains need to be defined among the 6 cluster nodes. The labels for each cluster node are as follows:
| Cluster Node | Label | Topological Domain |
|---|---|---|
| k8s-node-01 | az1:node01 | az1 |
| k8s-node-02 | az1:node02 | az1 |
| k8s-node-06 | az1:node03 | az1 |
| k8s-node-04 | az2:node01 | az2 |
| k8s-node-05 | az2:node02 | az2 |
| k8s-node-03 | az2:node03 | az2 |
2. Scheduling Configuration¶
The redis-leader and redis-follower replicas need to be scheduled in different topological domains, so separate affinity policies need to be configured as follows:
redis-leader
# Apply workload anti-affinity to the cluster nodes (k8s-node-01, k8s-node-02, k8s-node-06) within the topological domain __az1__, ensuring that only one leader replica is scheduled per cluster node.
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- redis-leader
topologyKey: az1
# Apply node affinity scheduling for the replicas of redis-leader within the topological domain __az1__ on cluster nodes (k8s-node-01, k8s-node-02, k8s-node-06)
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
preference:
matchExpressions:
- key: az1
operator: In
values:
- node01
- weight: 90
preference:
matchExpressions:
- key: az1
operator: In
values:
- node02
- weight: 80
preference:
matchExpressions:
- key: az1
operator: In
values:
- node03
redis-follower
# Apply workload anti-affinity to the cluster nodes (k8s-node-03, k8s-node-04, k8s-node-05) within the topological domain __az2__ for the replicas of redis-follower
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- redis-follower
topologyKey: az2
# Apply node affinity scheduling for the replicas of redis-follower within the topological domain __az2__ on cluster nodes (k8s-node-03, k8s-node-04, k8s-node-05)
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
preference:
matchExpressions:
- key: az2
operator: In
values:
- node01
- weight: 90
preference:
matchExpressions:
- key: az2
operator: In
values:
- node02
- weight: 80
preference:
matchExpressions:
- key: az2
operator: In
values:
- node03
Handling Data Center Offline¶
Data Center A Offline¶
When Data Center A is offline, two Redis-leader replicas will go offline, and the entire Redis cluster will be unable to provide normal services, as shown in the following diagram:
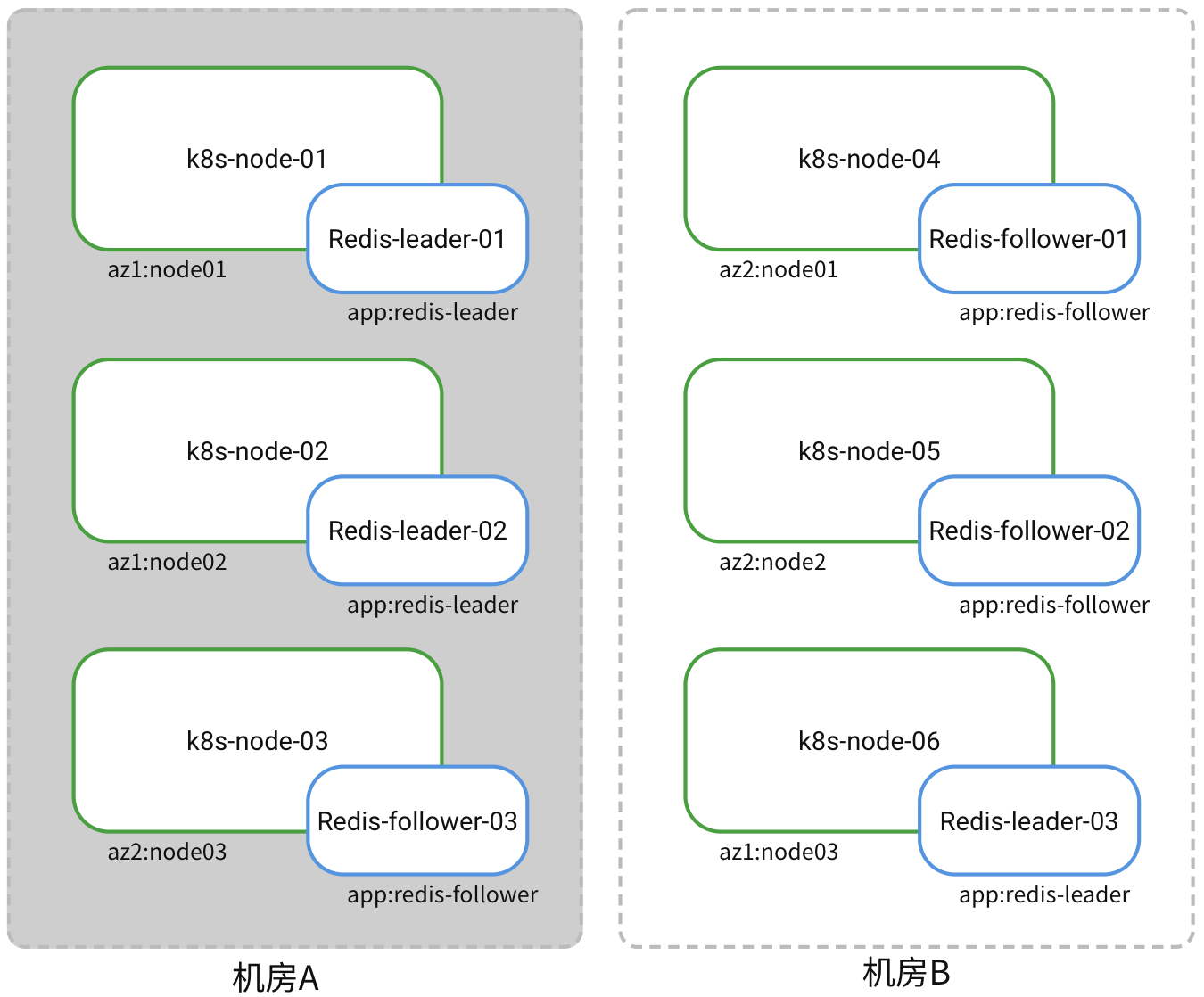
Solution
Use the redis-cli tool to connect to any redis-follower replica in Data Center B and manually convert it to a leader replica.
# Connect to a follower node
redis-cli -h <ip> -p <port>
# Password authentication, the password can be found in the instance overview page of the middleware module
auth <password>
# Perform role conversion for the node
cluster failover takeover
# Check the role information of the node, it should have changed
role
After the role conversion of a replica in Data Center B, the cluster can resume its service capability. When Data Center A comes back online, the original redis-leader replica will join the Redis instance as a follower.
Data Center B Offline¶
When Data Center B is offline, only one redis-leader replica will go offline, and the Redis service will not be interrupted. No manual intervention is required, as shown in the following diagram: