Karmada Failover 详解¶
作者:Fish-pro

多云时代,如何实现应用跨数据中心,跨可用区和跨集群高可用,成为我们探讨的新话题。 在单个集群中,如果集群发生故障,那么在集群中的所有应用将不可被访问。 是否有方式帮助我们在集群发生故障时,应用自动迁移到新的集群,保证应用持续的对外访问呢? 显然,Karmada 作为目前社区最火热的多云项目,提供了这样的能力。
Karmada (Kubernetes Armada) 使用户能够跨多个集群运行云原生应用,而不需更改已有的应用。 通过使用 Kubernetes 原生 API 提供高级调度功能,实现了真正开放的多云。Karmada 旨在为多云和混合云场景下的多集群应用管理提供便捷的自动化,具有集中式多云管理、高可用性和故障恢复等关键特性。 本文基于 Karmada 的 release 版本 v1.4.2,将和大家一起来探究一下 Karmada 跨集群的故障恢复是如何实现的 , 有哪些控制器和调度器参与到这个过程中,以及每个控制器在这个过程中承担了什么样的能力,调度器承担了什么样的能力, 以及如何保证用户业务的高可用性和连续性?
如果您在阅读本文之前,还未了解或使用过 Karmada,推荐阅读:
为什么需要故障转移¶
首先,我们来梳理一下,实现故障转移的必要性:
- 管理员在 Karmada 控制平面上部署离线应用,并将 Pod 实例分配到多个集群。 当集群发生故障时,管理员希望 Karmada 将故障集群中的 Pod 实例迁移到满足条件的其他集群中。
- 普通用户通过 Karmada 控制平面在集群中部署在线应用。应用包括数据库实例、服务器实例和配置文件。 此时,集群故障。客户希望将整个应用程序迁移到另一个合适的集群。在应用迁移过程中,确保业务不中断。
- 管理员升级集群后,集群中作为基础设施的容器网络和存储设备将发生变化。 管理员希望在升级集群前将集群中的应用迁移到其他合适的集群中。在迁移过程中,必须持续提供服务。
Karmada 故障恢复示例¶
Karmada 故障恢复支持两种方式:
- Duplicated (全量调度策略)。当满足 pp (propagationPolicy) 限制的未调度的候选集群数量不少于调度失败的集群数量时,将调度失败的集群重新调度到候选集群。
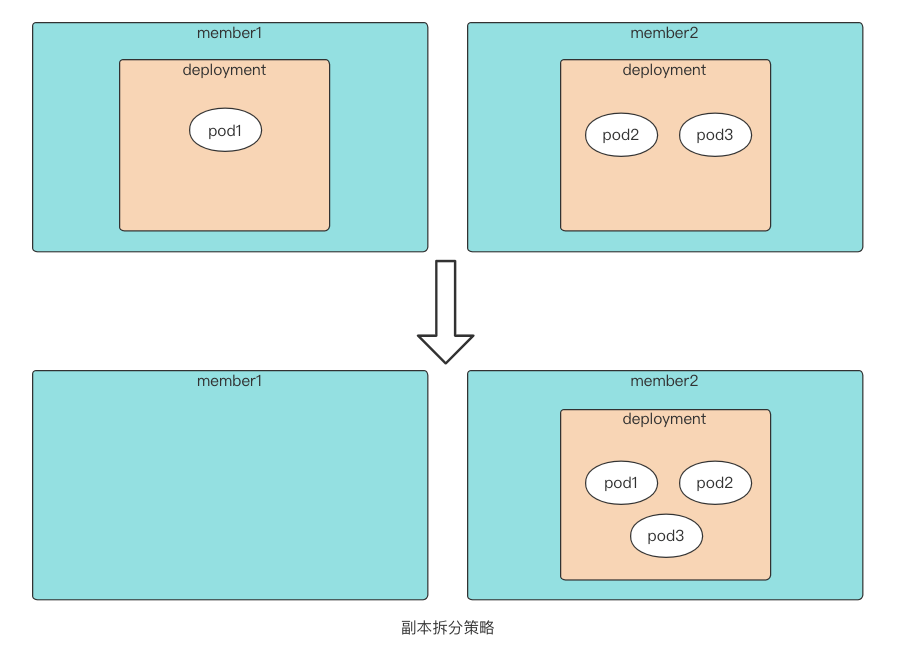
- Divided (副本拆分调度策略)。集群故障时,调度器和控制器配合尝试将故障集群副本迁移到其他运行正常的集群。
本文以 Divided 为例:
-
下载 Karmada 官方 v1.4.2 sourece code 后,使用 hack/local-up-karmada.sh ,启动本地的 Karmada。 启动后,自动纳管了三个工作集群,其中集群 member1 和 member2 使用 push 模式,member3 使用 pull 模式。
-
在 Karmada 控制平面部署如下的应用配置,可以发现我们定义了一个副本数为 3 的 nginx 的应用,同时定义了一个传播策略。 传播策略中,使用 clusterNames 的方式指定了集群亲和性,需要调度到集群 member1 和 member2 上。 同时在副本调度策略中,采用副本拆分的方式进行调度,遵循 member1 权重为 1,member2 权重为 2 的静态权重方式进行调度。
apiVersion: apps/v1 kind: Deployment metadata: name: nginx labels: app: nginx spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - image: nginx name: nginx --- apiVersion: policy.karmada.io/v1alpha1 kind: PropagationPolicy metadata: name: nginx-propagation spec: resourceSelectors: - apiVersion: apps/v1 kind: Deployment name: nginx placement: clusterAffinity: clusterNames: - member1 - member2 replicaScheduling: replicaDivisionPreference: Weighted replicaSchedulingType: Divided weightPreference: staticWeightList: - targetCluster: clusterNames: - member1 weight: 1 - targetCluster: clusterNames: - member2 weight: 2应用下发后,我们将会看到如下结果,集群 member1 上传播了一个副本数为 1 的 deployment,集群 member2 上传播了一个副本数为 2 的 deployment。 合计三个副本,符合我们调度预期。查看控制平面资源信息,发现在控制平面的成员集群对应执行命名空间下,创建了对应的 work, 这里的 work 即是通过传播策略和覆盖策略作用后实际需要在成员集群上传播的资源对象的载体, 同时,资源 deployment 的 rb (ResourceBinding) 中看到,deployment 调度到了集群 member1 和集群 member2。
NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/nginx 3/3 3 3 2m NAME AGE propagationpolicy.policy.karmada.io/nginx-propagation 119s... spec: clusters: - name: member2 replicas: 2 - name: member2 replicas: 1 replicas: 3 resource: apiVersion: apps/v1 kind: Deployment name: nginx namespace: default resourceVersion: "5776" uid: 530aa301-760a-48a7-ada0-fc3a2112564b ... -
模拟集群发生故障,由于安装集群是使用 kind 启动的,那么我们直接暂停集群 member1 的容器, 模拟实际情况中,集群由于网络或者集群本身问题,从而在联邦中失联。
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8794507af450 kindest/node:v1.23.4 "/usr/local/bin/entr…" 52 minutes ago Up 51 minutes 127.0.0.1:40000->6443/tcp member2-control-plane cc57b0eb54fe kindest/node:v1.23.4 "/usr/local/bin/entr…" 52 minutes ago Up 51 minutes 127.0.0.1:35728->6443/tcp karmada-host-control-plane 5ac1815cd40e kindest/node:v1.23.4 "/usr/local/bin/entr…" 52 minutes ago Up 51 minutes 127.0.0.1:39837->6443/tcp member1-control-plane f5e5f753dcb8 kindest/node:v1.23.4 "/usr/local/bin/entr…" 52 minutes ago Up 51 minutes 127.0.0.1:33529->6443/tcp member3-control-plane暂停成功,我们再来看一下实际情况,可以发现,集群暂停成功后,控制平面的 resource template 状态依然是 '3/3',符合整体的预期。 获取成员集群上的 deployment,集群 member1 网络不可达。集群 membe2 上获取到了副本数为 3 的 deployment,故障发生后集群 member2 新增了 1 个副本。 通过查看 Karmada 资源 rb (rersourcebinding) 和 pp(propagationPolicy) 后,可以发现,故障转移后,deployment 的资源绑定只调度到集群 member2。 但是有个问题,从 rb (rersourcebinding) 的配置中,我们可以看到,此时资源未调度到集群 member1,但是此时集群 member1 对应的执行命名空间下仍然存在对应的 work,这是为什么呢?不急,我们来继续进一步探究。
NAME VERSION MODE READY AGE member1 v1.23.4 Push False 43m member2 v1.23.4 Push True 43m member3 v1.23.4 Pull True 42mNAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/nginx 3/3 3 3 11m NAME AGE propagationpolicy.policy.karmada.io/nginx-propagation 11mNAME CLUSTER READY UP-TO-DATE AVAILABLE AGE ADOPTION nginx member2 3/3 3 3 12m Y error: cluster(member1) is inaccessible, please check authorization or networkNAME CLUSTER READY STATUS RESTARTS AGE nginx-85b98978db-8zj5k member2 1/1 Running 0 3m18s nginx-85b98978db-d7q92 member2 1/1 Running 0 12m nginx-85b98978db-xmbp9 member2 1/1 Running 0 12m error: cluster(member1) is inaccessible, please check authorization or network... spec: clusters: - name: member2 replicas: 3 replicas: 3 resource: apiVersion: apps/v1 kind: Deployment name: nginx namespace: default resourceVersion: "5776" uid: 530aa301-760a-48a7-ada0-fc3a2112564b ...将集群状态恢复,模拟集群被运维管理员修复的情况,此时副本的变化又将会如何呢? 可以发现,当故障集群恢复后,集群 member2 上的副本数不变,同时,控制平面在集群 member1 对应执行命名空间下的 work 被删除,集群 member1 上的 deployment 被删除。
NAME VERSION MODE READY AGE member1 v1.23.4 Push True 147m member2 v1.23.4 Push True 147m member3 v1.23.4 Pull True 146mNAME CLUSTER READY STATUS RESTARTS AGE pod/nginx-85b98978db-2p8hn member2 1/1 Running 0 73m pod/nginx-85b98978db-7j8xs member2 1/1 Running 0 73m pod/nginx-85b98978db-m897g member2 1/1 Running 0 70m NAME CLUSTER READY UP-TO-DATE AVAILABLE AGE deployment.apps/nginx member2 3/3 3 3 73m```shel(images kubectl get work | grep nginx
从以上的示例,我们可以发现,当集群发生故障时,Karmada 会自动调节其余成员集群上的副本, 从而来满足用户整体的副本期望,从而达到集群级别的故障恢复。当故障集群恢复后,转移的副本会保持不变, 原有调度集群上资源会被删除,资源不会调度回故障的集群。
Karmada 故障恢复实现原理¶
在多集群场景下,用户应用可能部署在多个集群中,以提高业务的高可用性。 在 Karmada 中,当集群发生故障或用户不想继续在集群上运行应用时,集群状态将被标记为不可用,并添加两个污点。 (images(images 检测到集群故障后,控制器将从故障集群中移除应用。然后,被移除的应用将被调度到满足要求的其他集群。 这样可以实现故障转移,保证用户业务的高可用性和连续性。
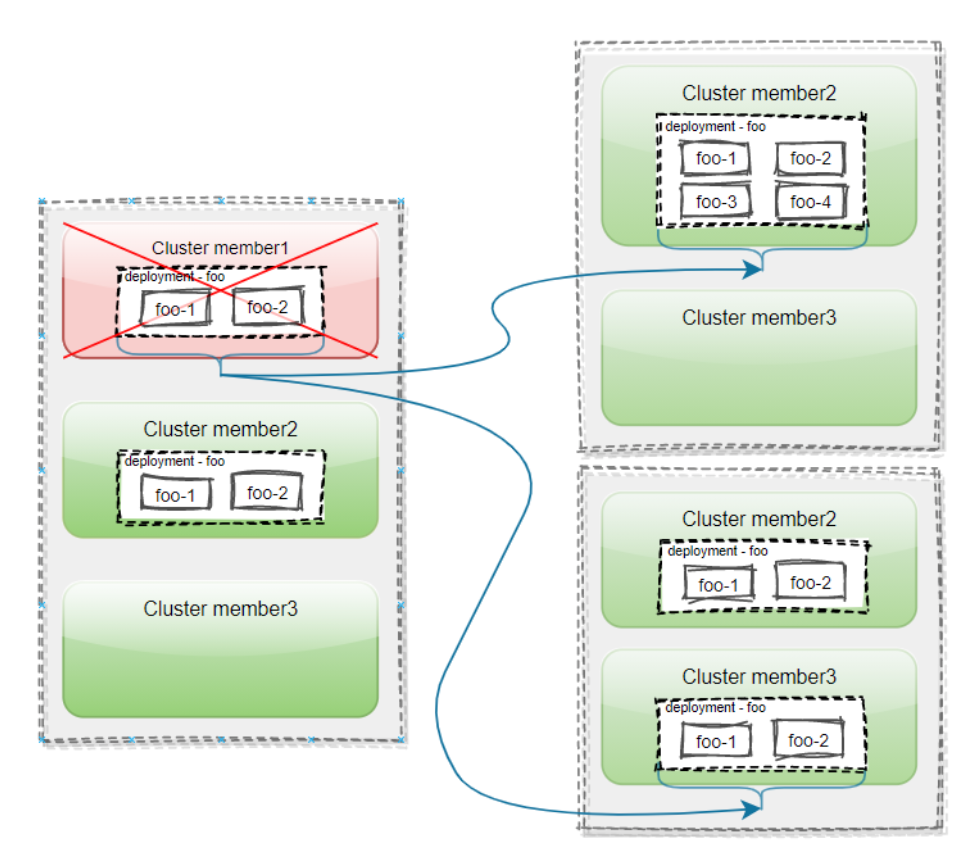
图源:Karmada 官方文档 https://karmada.io
如上图,用户在 Karmada 中加入了三个集群: member1、member2 和 member3。 部署一个名为 foo 的 deployment,它有两个副本,在 Karmada 控制平面上创建。 通过使用 pp (PropagationPolicy) 将 deployement 传播到集群 member1 和 member2。
当集群 member1 发生故障时,如果是副本拆分策略,集群 member1 上的 Pod 将被清除并迁移到满足要求的集群 member2。 如果是全量策略,集群 member1 上的 deployment 将会被移除并迁移到满足要求的集群 member3。
Karmada 实现故障转移,主要由 karmada-controller-manager 中的 6 个控制器和 karmada-scheduler 参与完成。
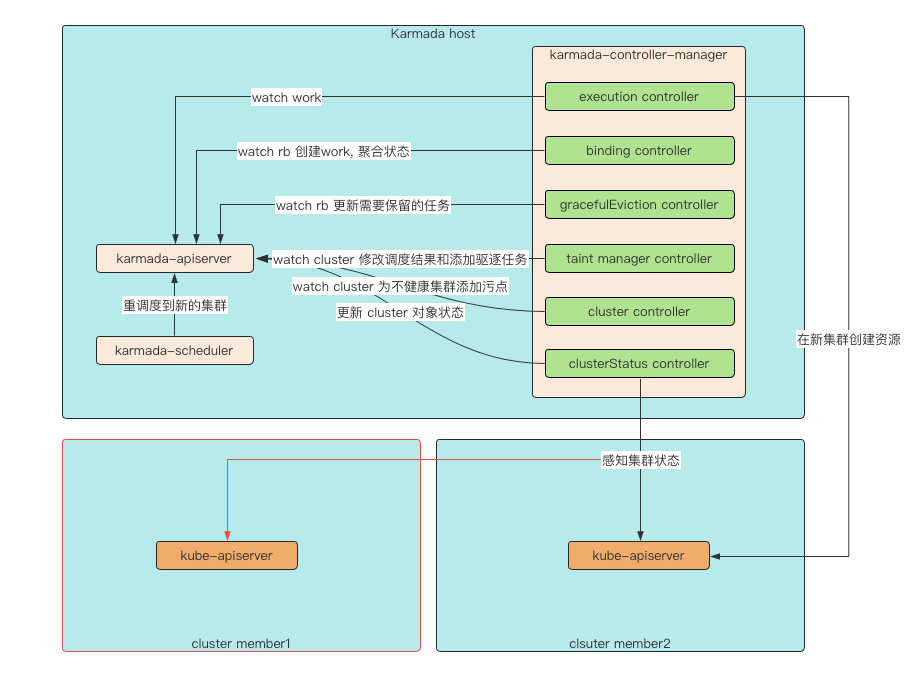
- clusterStatus controller:感知集群状态,并将集群状态写入到控制平面的 cluster 资源对象的状态中。
- cluster controller:在控制平面创建执行命名空间(这里的执行命名空间指的是 Karmada 会在控制平面为每一个成员集群创建一个具有特殊命名规则的命名空间,该命名空间用于存放 work ),根据 conditions 判断是否需要为集群打上污点。
- taint-manager controller:根据集群污点,传播策略中容忍的集群污点,对比计算,确定是否要将集群上的资源驱逐。
- karmada-scheduler:根据传播策略和集群情况,为资源选择最佳的调度集群。
- gracefulEviction controller:保证在新的集群上的资源状态健康后,再移除驱逐集群上的资源对象。
- binding controller:根据调度结果,应用传播策略中的规则,在控制平面集群对应执行命名空间下创建 work, 聚合 work 状态,更新 rb(ResourceBinding) 和 resource template 状态。
- execution controller:根据成员集群对应执行命名空间下的 work, 在成员集群中创建资源。
接下来看一下每个控制器和调度器,在集群故障恢复的场景中,分别承担了什么样的能力。
clusterStatus controller¶
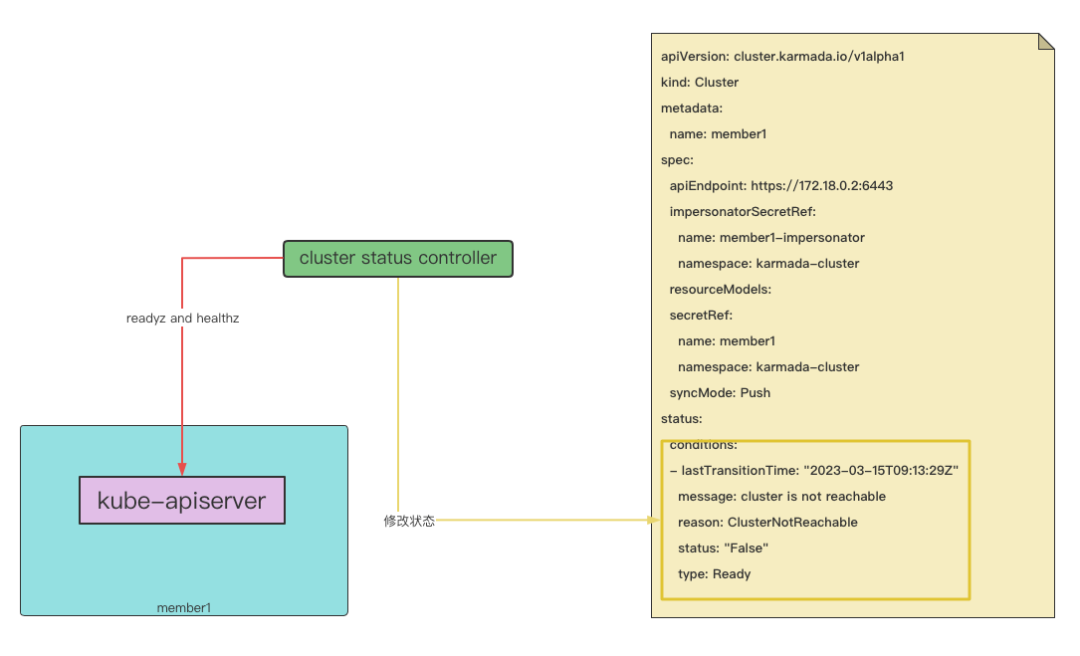
clusterStatus controller 主要用于同步集群实际状态。当集群无法访问时,clusterStatus controller 就会感知到集群状态处于非在线状态,此时便会更新控制平面的 cluster 资源对象的状态,修改 conditions 中 type 为 Ready 的 condition 状态为 ‘False’, 以下为主要实现代码。
首先,通过访问成员集群 kube-apiserver 的 ‘/readyz’ 和 ‘/healthz’,获取到成员集群的在线状态和健康状态。
func getClusterHealthStatus(clusterClient *util.ClusterClient) (online, healthy bool) {
healthStatus, err := healthEndpointCheck(clusterClient.KubeClient, "/readyz")
if err != nil && healthStatus == http.StatusNotFound {
// do health check with healthz endpoint if the readyz endpoint is not installed in member cluster
healthStatus, err = healthEndpointCheck(clusterClient.KubeClient, "/healthz")
}
if err != nil {
klog.Errorf("Failed to do cluster health check for cluster %v, err is : %v ", clusterClient.ClusterName, err)
return false, false
}
if healthStatus != http.StatusOK {
klog.Infof("Member cluster %v isn't healthy", clusterClient.ClusterName)
return true, false
}
return true, true
}
其次,根据在线状态和健康状态初始化 conditions。
func generateReadyCondition(imagesalthy bool) metav1.Condition {
if !online {
return util.NewCondition(clusterv1alpha1.ClusterConditionReady, clusterNotReachableReason, clusterNotReachableMsg, metav1.ConditionFalse)
}
if !healthy {
return util.NewCondition(clusterv1alpha1.ClusterConditionReady, clusterNotReady, clusterUnhealthy, metav1.ConditionFalse)
}
return util.NewCondition(clusterv1alpha1.ClusterConditionReady, clusterReady, clusterHealthy, metav1.ConditionTrue)
}
最后,如果集群已经下线,此时初始化的 condition 状态不为 ‘True’, 则认为需要更新 cluster 资源对象的 condiitions。 conditions 中 type 为 Ready 的 condition 状态将会被修改为 ‘False’,然后返回。
online, healthy := getClusterHealthStatus(clusterClient)
observedReadyCondition := generateReadyCondition(online, healthy)
readyCondition := c.clusterConditionCache.thresholdAdjustedReadyCondition(cluster, &observedReadyCondition)
// cluster is offline after retry timeout, update cluster status immediately and return.
if !online && readyCondition.Status != metav1.ConditionTrue {
klog.V(2).Infof("Cluster(%s) still offline after %s, ensuring offline is set.",
cluster.Name, c.ClusterFailureThreshold.Duration)
setTransitionTime(cluster.Status.Conditions, readyCondition)
meta.SetStatusCondition(¤tClusterStatus.Conditions, *readyCondition)
return c.updateStatusIfNeeded(cluster, currentClusterStatus)
}
cluster controller¶
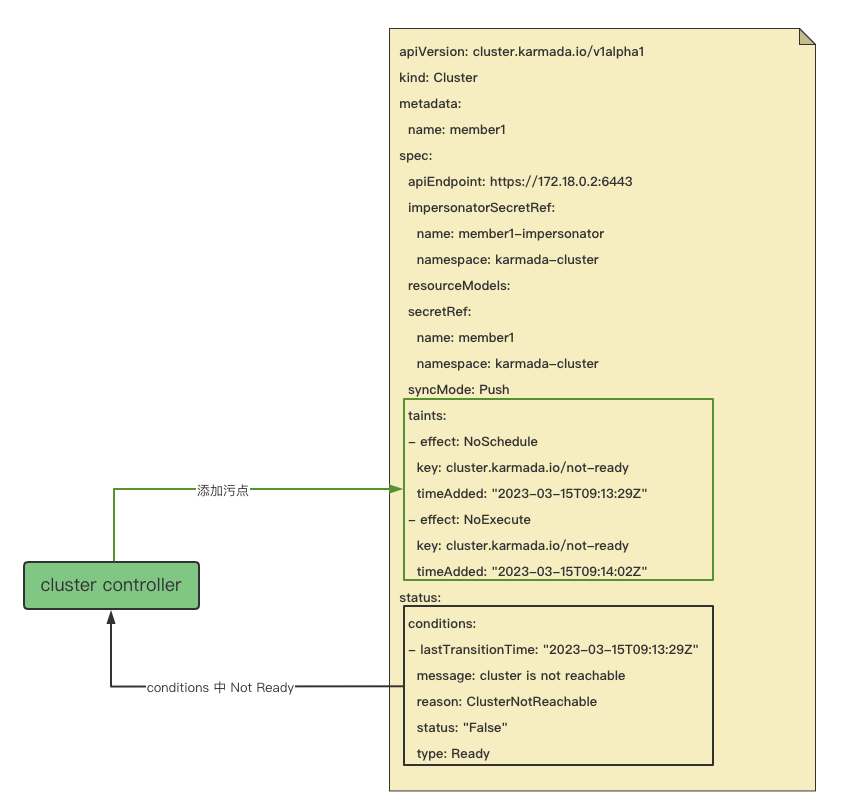
cluster conntroller 会根据集群当前状态下的 conditions,判断是否需要为集群打上不可调度和不可执行的污点。 以下代码为核心实现逻辑,当 conditions 中 type 为 Ready 的 condition 状态为 'False' 时, 执行 UpdateClusterControllerTaint 函数添加 effect 为 NoSchedule 污点。 此污点并不会触发驱逐操作。想要触发驱逐操作,你还需要将 NoExecute 作为污点添加到 taint-manager。
func (c *Controller) taintClusterByCondition(ctx context.Context, cluster *clusterv1alpha1.Cluster) error {
currentReadyCondition := meta.FindStatusCondition(cluster.Status.Conditions, clusterv1alpha1.ClusterConditionReady)
var err error
if currentReadyCondition != nil {
switch currentReadyCondition.Status {
case metav1.ConditionFalse:
// Add NotReadyTaintTemplateForSched taint immediately.
if err = utilhelper.UpdateClusterControllerTaint(ctx, c.Client, []*corev1.Taint{NotReadyTaintTemplateForSched}, []*corev1.Taint{UnreachableTaintTemplateForSched}, cluster); err != nil {
klog.ErrorS(err, "Failed to instantly update UnreachableTaintForSched to NotReadyTaintForSched, will try again in the next cycle.", "cluster", cluster.Name)
}
case metav1.ConditionUnknown:
// Add UnreachableTaintTemplateForSched taint immediately.
if err = utilhelper.UpdateClusterControllerTaint(ctx, c.Client, []*corev1.Taint{UnreachableTaintTemplateForSched}, []*corev1.Taint{NotReadyTaintTemplateForSched}, cluster); err != nil {
klog.ErrorS(err, "Failed to instantly swap NotReadyTaintForSched to UnreachableTaintForSched, will try again in the next cycle.", "cluster", cluster.Name)
}
case metav1.ConditionTrue:
if err = utilhelper.UpdateClusterControllerTaint(ctx, c.Client, nil, []*corev1.Taint{NotReadyTaintTemplateForSched, UnreachableTaintTemplateForSched}, cluster); err != nil {
klog.ErrorS(err, "Failed to remove schedule taints from cluster, will retry in next iteration.", "cluster", cluster.Name)
}
}
} else {
// Add NotReadyTaintTemplateForSched taint immediately.
if err = utilhelper.UpdateClusterControllerTaint(ctx, c.Client, []*corev1.Taint{NotReadyTaintTemplateForSched}, nil, cluster); err != nil {
klog.ErrorS(err, "Failed to add a NotReady taint to the newly added cluster, will try again in the next cycle.", "cluster", cluster.Name)
}
}
return err
}
taint-manager controller¶
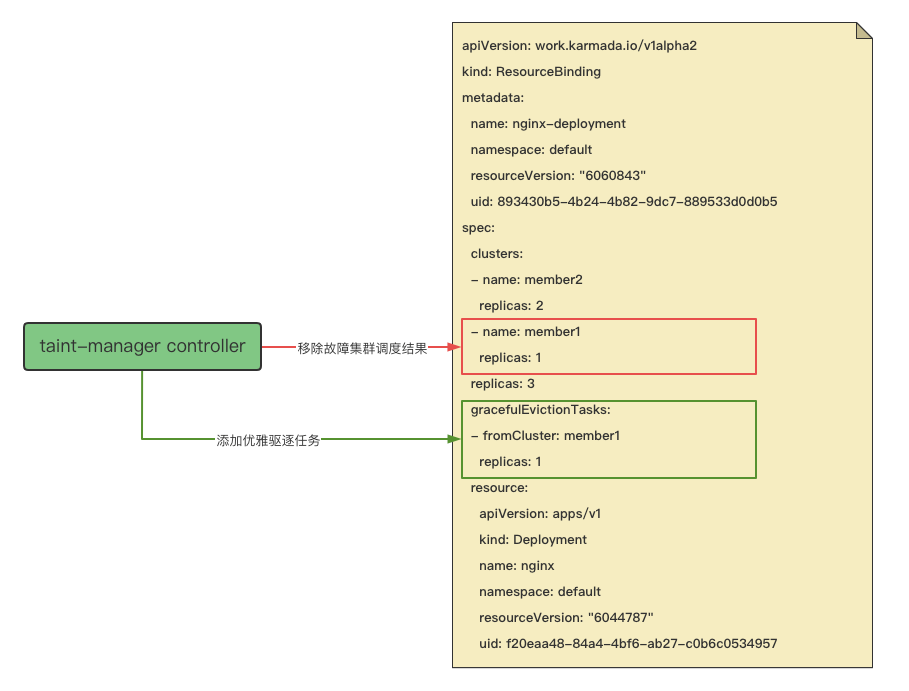
taint-manager controller 控制器随 cluster controller 同步启动,可参数配置是否启动,默认启动。 它感知 cluster 资源对象的变更事件,当感知到集群拥有 effect 为 NoExecute 的污点时, 会获取到该集群上的所有命名空间级别和集群级别的 rb (ResourceBinding),然后放入对应的驱逐处理队列。 驱逐处理消费者(worker)会判断获取到 rb(ResourceBinding) 对应的 pp (PropagationPolicy),看 pp (PropagationPolicy) 中是否存在集群污点容忍,如果 pp (PropagationPolicy) 中的集群污点容忍和集群污点匹配, 那么直接跳过,认为该集群上的资源不需要驱逐。否则认为需要驱逐。如果需要驱逐,那么此时会判断是否开启了优雅驱逐, 优雅驱逐默认开启,为 rb (ResourceBinding) 对象写入优雅驱逐任务,即 rb.spec.gracefulEvictionTasks 中增加一条优雅驱逐任务。
needEviction, tolerationTime, err := tc.needEviction(cluster, binding.Annotations)
if err != nil {
klog.ErrorS(err, "Failed to check if binding needs eviction", "binding", fedKey.ClusterWideKey.NamespaceKey())
return err
}
// Case 1: Need eviction now.
// Case 2: Need eviction after toleration time. If time is up, do eviction right now.
// Case 3: Tolerate forever, we do nothing.
if needEviction || tolerationTime == 0 {
// update final result to evict the target cluster
if features.FeatureGate.Enabled(features.GracefulEviction) {
binding.Spec.GracefulEvictCluster(cluster, workv1alpha2.EvictionProducerTaintManager, workv1alpha2.EvictionReasonTaintUntolerated, "")
} else {
binding.Spec.RemoveCluster(cluster)
}
if err = tc.Update(context.TODO(), binding); err != nil {
helper.EmitClusterEvictionEventForResourceBinding(binding, cluster, tc.EventRecorder, err)
klog.ErrorS(err, "Failed to update binding", "binding", klog.KObj(binding))
return err
}
if !features.FeatureGate.Enabled(features.GracefulEviction) {
helper.EmitClusterEvictionEventForResourceBinding(binding, cluster, tc.EventRecorder, nil)
}
} else if tolerationTime > 0 {
tc.bindingEvictionWorker.AddAfter(fedKey, tolerationTime)
}
可以发现,写入驱逐任务时,会将优雅驱逐任务对应的集群,从 rb.spec.clusters 中移除,也就是会修改调度结果 (这里需要特别说明一下,调度结果就是 Karmada 调度器根据传播策略和集群情况为资源选择的调度分发集群, 调度结果会记录在 rb (ResourceBinding) 的 spec.clusters 属性中)。 也就是说由于集群故障,会触发调度器重新调度,资源应该从故障的集群上驱逐,在新的集群上创建。
// This function no-(images cluster does not exist.
func (s *ResourceBindingSpec) GracefulEvictCluster(name, producer, reason, message string) {
// find the cluster index
var i int
for i = 0; i < len(s.Clusters); i++ {
if s.Clusters[i].Name == name {
break
}
}
// not found, do nothing
if i >= len(s.Clusters) {
return
}
// build eviction task
evictingCluster := s.Clusters[i].DeepCopy()
evictionTask := GracefulEvictionTask{
FromCluster: evictingCluster.Name,
Reason: reason,
Message: message,
Producer: producer,
}
if evictingCluster.Replicas > 0 {
evictionTask.Replicas = &evictingCluster.Replicas
}
s.GracefulEvictionTasks = append(s.GracefulEvictionTasks, evictionTask)
s.Clusters = append(s.Clusters[:i], s.Clusters[i+1:]...)
}
Karmada scheduler¶
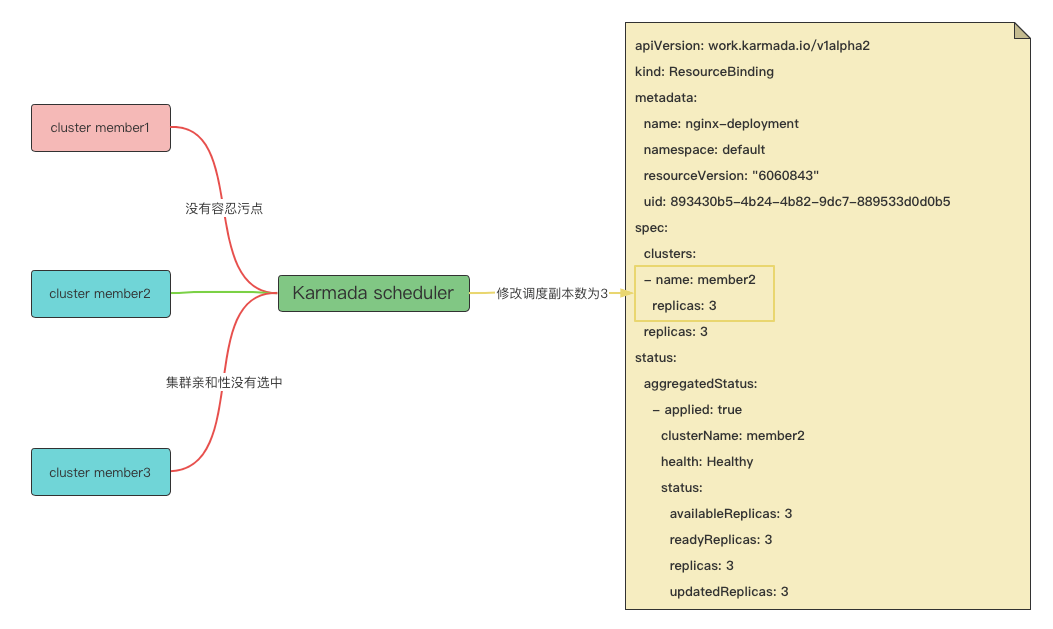
Karmada scheduler,如果调度的目标副本和期望的目标副本不等,也就是当 rb.spec.clusters(资源调度集群结果)下所有的副本之和不等于 rb.spec.replicas(资源期望副本)时,调度器认为这是一次扩容或者缩容操作,从而触发重调度操作。 而在 taint-manager controller 中,由于集群故障,资源从故障集群上驱逐了,taint-manger controller 修改了调度结果,移除了 rb.spec.clusters 下的一个集群,导致 rb.spec.clusters 下所有的副本之和小于 rb.spec.replicas,所以这是一次扩容操作。
这里是否需要重新调度的判断,核心逻辑为 ‘replicasSum != bindingSpec.Replicas’。 移除了调度结果中的集群 member1 的调度结果,所以此时 replicasSum 值为 2, 但是 bindingSpec.Replicas 值为 3,两者不等所以函数返回值为真。
// IsBindingReplicasChanged will check if the sum of replicas is different from the replicas of object
func IsBindingReplicasChanged(bindingSpec *workv1alpha2.ResourceBindingSpec, strategy *policyv1alpha1.ReplicaSchedulingStrategy) bool {
if strategy == nil {
return false
}
if strategy.ReplicaSchedulingType == policyv1alpha1.ReplicaSchedulingTypeDuplicated {
for _, targetCluster := range bindingSpec.Clusters {
if targetCluster.Replicas != bindingSpec.Replicas {
return true
}
}
return false
}
if strategy.ReplicaSchedulingType == policyv1alpha1.ReplicaSchedulingTypeDivided {
replicasSum := GetSumOfReplicas(bindingSpec.Clusters)
return replicasSum != bindingSpec.Replicas
}
return false
}
由于函数 IsBindingReplicasChanged 返回为真,并且设置了 ReplicaScheduling,则会执行重调度操作。
if rb.Spec.Placement.ReplicaScheduling != nil && util.IsBindingReplicasChanged(&rb.Spec, rb.Spec.Placement.ReplicaScheduling) {
// binding replicas changed, need reschedule
klog.Infof("Reschedule ResourceBinding(%s/%s) as replicas scaled down or scaled up", namespace, name)
err = s.scheduleResourceBinding(rb)
metrics.BindingSchedule(string(ScaleSchedule), utilmetrics.DurationInSeconds(start), err)
return err
}
在重调度逻辑中,由于集群 member1 存在污点,所以会被调度插件过滤掉,集群 member3 没有被集群亲和性选中。结果,只有 member2 满足要求。
// Filter checks if the given tolerations in placement tolerate cluster's taints.
func (p *TaintToleration) Filter(
_ context.Context,
bindingSpec *workv1alpha2.ResourceBindingSpec,
_ *workv1alpha2.ResourceBindingStatus,
cluster *clusterv1alpha1.Cluster,
) *framework.Result {
// skip the filter if the cluster is already in the list of scheduling results,
// if the workload referencing by the binding can't tolerate the taint,
// the taint-manager will evict it after a graceful period.
if bindingSpec.TargetContains(cluster.Name) {
return framework.NewResult(framework.Success)
}
filterPredicate := func(t *corev1.Taint) bool {
return t.Effect == corev1.TaintEffectNoSchedule || t.Effect == corev1.TaintEffectNoExecute
}
taint, isUntolerated := v1helper.FindMatchingUntoleratedTaint(cluster.Spec.Taints, bindingSpec.Placement.ClusterTolerations, filterPredicate)
if !isUntolerated {
return framework.NewResult(framework.Success)
}
return framework.NewResult(framework.Unschedulable, fmt.Sprintf("cluster(s) had untolerated taint {%s}", taint.ToString()))
}
在计算调度副本时,由于设置了静态权重,所以要以静态权重方式 (静态权重方式是指,根据管理员设定的比例对副本进行拆分,举例,如果期望副本总数为 9, 集群 member1 静态权重为 1,集群 member2 静态权重为 2,那么集群 member1 上的副本计算方式是 9*⅓=3, 集群 member2 上的副本计算方式为 9*⅔=6)进行副本拆分。但是,因为只有一个集群满足要求, 所以在设置集群调度副本时,集群 member2 的副本调度结果为 3,所以调度器会将 rb.spec.clusters (资源调度集群结果)下的集群 member2 上的副本调度结果由 2 修改为 3。
// TakeByWeight divide replicas by a weight list and merge the result into previous result.
func (a *Dispenser) TakeByWeight(w ClusterWeightInfoList) {
if a.Done() {
return
}
sum := w.GetWeightSum()
if sum == 0 {
return
}
sort.Sort(w)
result := make([]workv1alpha2.TargetCluster, 0, w.Len())
remain := a.NumReplicas
for _, info := range w {
replicas := int32(info.Weight * int64(a.NumReplicas) / sum)
result = append(result, workv1alpha2.TargetCluster{
Name: info.ClusterName,
Replicas: replicas,
})
remain -= replicas
}
// TODO(Garrybest): take rest replicas by fraction part
for i := range result {
if remain == 0 {(image(images
break
}
result[i].Replicas++
remain--
}
a.NumReplicas = remain
a.Result = util.MergeTargetClusters(a.Result, result)
}
以下为故障恢复时,截取调度器部分日志,可以清晰看到整个集群筛选和副本计算的过程。 集群 member1 由于没有容忍污点被过滤掉,集群 member3 没有被集群亲和性选中被过滤掉,最终调度结果为集群 member2,调度副本为 3。
I0217 06:46:53.057843 1 scheduler.go:390] Reschedule ResourceBinding(default/nginx-deployment) as replicas scaled down or scaled up
I0217 06:46:53.057888 1 scheduler.go:473] "Begin scheduling resource binding" resourceBinding="default/nginx-deployment"
I0217 06:46:53.083460 1 generic_scheduler.go:119] cluster "member3" is not fit, reason: cluster(s) didn't match the placement cluster affinity constraint
I0217 06:46:53.083524 1 generic_scheduler.go:119] cluster "member1" is not fit, reason: cluster(s) had untolerated taint {cluster.karmada.io/not-ready: }
I0217 06:46:53.083542 1 generic_scheduler.go:73] feasible clusters found: [member2]
I0217 06:46:53.083567 1 generic_scheduler.go:146] Plugin ClusterLocality scores on default/nginx => [{member2 100}]
I0217 06:46:53.083590 1 generic_scheduler.go:146] Plugin ClusterAffinity scores on default/nginx => [{member2 0}]
I0217 06:46:53.083601 1 generic_scheduler.go:79] feasible clusters scores: [{member2 100}]
I0217 06:46:53.085488 1 util.go:72] Target cluster: [{member2 99}]
I0217 06:46:53.085532 1 select_clusters.go:19] select all clusters
I0217 06:46:53.085548 1 generic_scheduler.go:85] selected clusters: [member2]
I0217 06:46:53.085571 1 scheduler.go:489] ResourceBinding default/nginx-deployment scheduled to clusters [{member2 3}]
I0217 06:46:53.151403 1 scheduler.go:491] "End scheduling resource binding" resourceBinding="default/nginx-deployment"
gracefulEviction controller¶
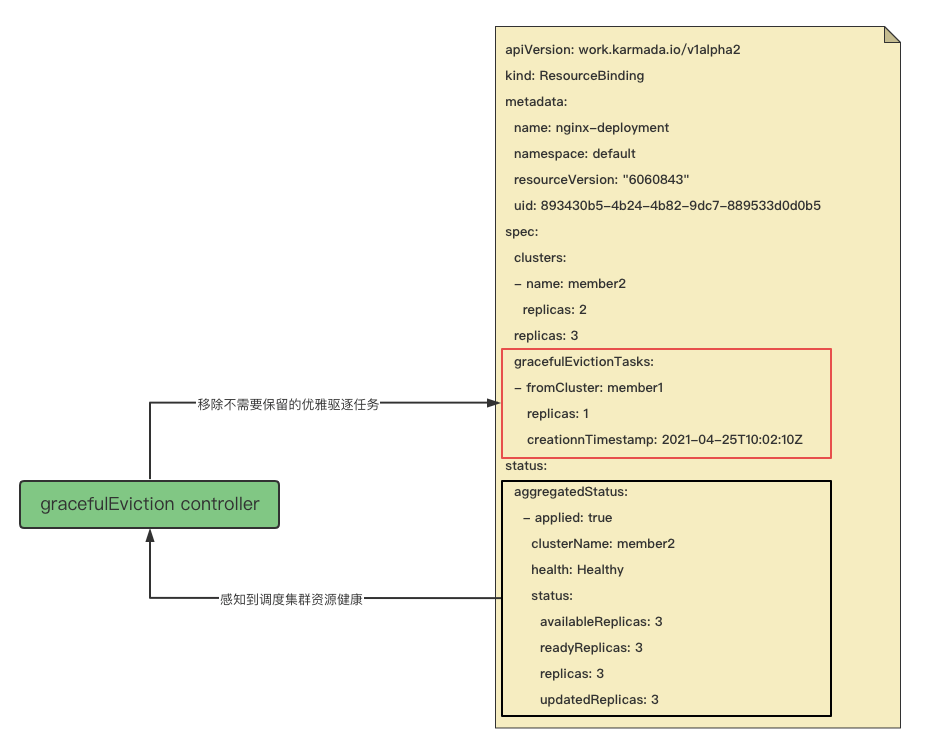
gracefulEviction controller 感知带有 rb.spec.gracefulEvictionTasks 的 rb(ResourceBinding) 资源的变更, 即只关心需要优雅驱逐的 rb (ResourceBinding)。然后根据调度目标集群,获取到调度结果集群的资源健康状态, 如果调度目标集群所有资源健康,则认为不需要保留优雅驱逐任务,从而移除驱逐集群任务,也就是将集群 member1 上的优雅驱逐任务移除。从中我们可以发现,优雅驱逐实现的逻辑是,保证了新的副本在符合要求的集群上 Ready 后, 再移除优雅驱逐任务,也就是才能删除调度到故障集群的旧资源。
// assessEvictionTasks assesses each task according to graceful eviction rules and
// returns the tasks that should be kept.
func assessEvictionTasks(bindingSpec workv1alpha2.ResourceBindingSpec,
obse(images[]workv1alpha2.AggregatedStatusItem,
timeout time.Duration,
now metav1.Time,
) ([]workv1alpha2.GracefulEvictionTask, []string) {
var keptTasks []workv1alpha2.GracefulEvictionTask
var evictedClusters []string
for _, task := range bindingSpec.GracefulEvictionTasks {
// set creation timestamp for new task
if task.CreationTimestamp.IsZero() {
task.CreationTimestamp = now
keptTasks = append(keptTasks, task)
continue
}
// assess task according to observed status
kt := assessSingleTask(task, assessmentOption{
scheduleResult: bindingSpec.Clusters,
timeout: timeout,
observedStatus: observedStatus,
})
if kt != nil {
keptTasks = append(keptTasks, *kt)
} else {
evictedClusters = append(evictedClusters, task.FromCluster)
}
}
return keptTasks, evictedClusters
}
binding controller¶
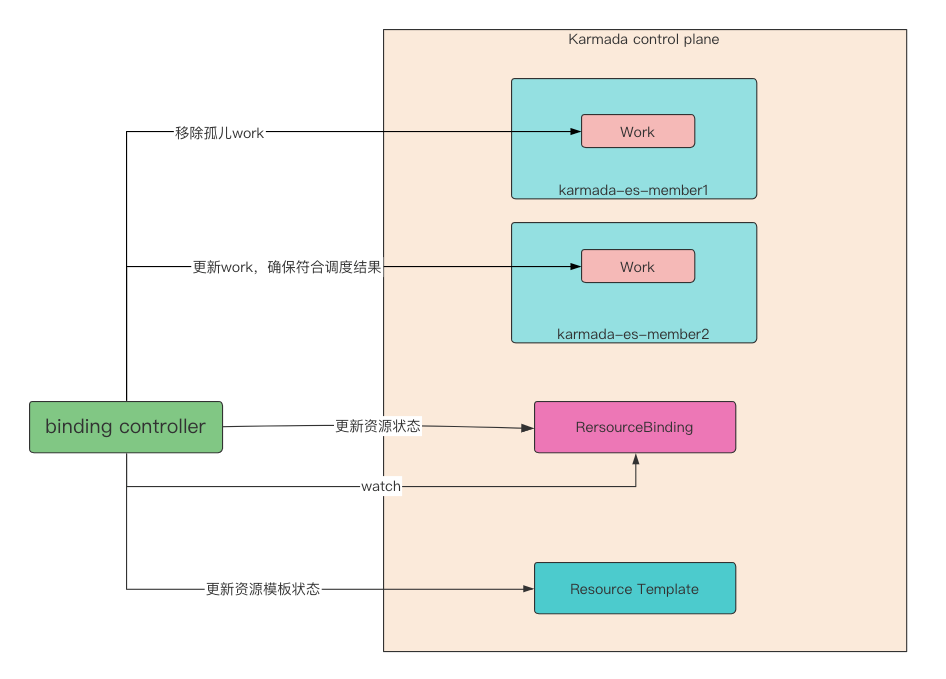
当 rb (ResourceBinding) 资源发生变更时,会被 binding controller 所感知。 首先会移除孤儿 work(work 用于存放经过传播策略规则后,在成员集群上需要真正创建的资源对象模板。 孤儿 work 是指,带有 rb (ReesourceBinding)资源对应标签的,但是随着 rb 的变更,work 已不是 rb 所期望的 work)。 除了 rb(ResourceBinding) 中三种属性中包含的集群,其他集群对应的执行命名空间下的 work 都会认为是孤儿 work: 第一种是 rb.spec.clusters,资源调度集群结果;第二种是 rb.spec.requiredBy,依赖应用的资源列表集群; 第三种是 rb.spec.gracefulEvictionTasks,优雅驱逐任务中的集群。在 gracefulEviction controller 中, 我们知道,需要新调度集群资源 Ready 后,任务才能被删除。这里就很巧妙, 这样就能保证新启动的副本在符合要求的集群上 Ready 之前,故障集群 work 永远不会被移除。
在示例中,可以发现当故障转移发生后,故障集群对应执行命名空间下仍然存在 work,理论上, 故障集群下 work 已经被判定为孤儿,为什么没有删除成功呢。进一步探究会发现,集群 member1 命名空间下的 work 的 DeletionTimestamp 不为空。没删除的原因是 work 存在 finalizer, 该 finalizer 是 binding controller 创建 work 时添加的。这里不能直接移除 work 的原因是, 需要保证在成员集群上的资源被移除后,才能移除 work。否则直接移除 work,会导致集群 member1 恢复后, 集群 member1 上的资源被保留,造成资源残留。所以,需要等待故障集群恢复后,execution controller 移除 work 对应在成员集群上的资源成功后,才能移除 finalizer,这样 work 就会被删除。
...
apiVersion: work.karmada.io/v1alpha1
kind: Work
metadata:
annotations:
resourcebinding.karmada.io/name: nginx-deployment
resourcebinding.karmada.io/namespace: default
creationTimestamp: "2023-02-17T08:53:08Z"
deletionGracePeriodSeconds: 0
deletionTimestamp: "2023-02-17T08:55:39Z"
finalizers:
- karmada.io/execution-controller
generation: 2
labels:
resourcebinding.karmada.io/key: 687f7fb96f
name: nginx-687f7fb96f
namespace: karmada-es-member1
resourceVersion: "28134"
uid: d215a03c-522d-4a89-9c5d-e87e27338a03
...
以下为 binding controller 的核心代码,核心逻辑是:
- 移除孤儿 work;
- 确保 rb (ResourceBinding) 期望 work 符合预期;
- 聚合 work 的状态,记录到 rb (ResourceBinding) 的状态中;
- 根据 rb (ResourceBinding) 的聚合状态,更新 resource template 状态, resource template 是指存放在 Karmada 控制平面上的资源模板对象。
// syncBinding will sync resourceBinding to Works.
func (c *ResourceBindingController) syncBinding(binding *workv1alpha2.ResourceBinding) (controllerruntime.Result, error) {
if err := c.removeOrphanWorks(binding); err != nil {
return controllerruntime.Result{Requeue: true}, err
}
workload, err := helper.FetchWorkload(c.DynamicClient, c.InformerManager, c.RESTMapper, binding.Spec.Resource)
if err != nil {
if apierrors.IsNotFound(err) {
// It might happen when the resource template has been removed but the garbage collector hasn't removed
// the ResourceBinding which dependent on resource template.
// So, just return without retry(requeue) would save unnecessary loop.
return controllerruntime.Result{}, nil
}
klog.Errorf("Failed to fetch workload for resourceBinding(%s/%s). Error: %v.",
binding.GetNamespace(), binding.GetName(), err)
return controllerruntime.Result{Requeue: true}, err
}
var errs []error
start := time.Now()
err = ensureWork(c.(imagesesourceInterpreter, workload, c.OverrideManager, binding, apiextensionsv1.NamespaceScoped)
metrics.ObserveSyncWorkLatency(binding.ObjectMeta, err, start)
if err != nil {
klog.Errorf("Failed to transform resourceBinding(%s/%s) to works. Error: %v.",
binding.GetNamespace(), binding.GetName(), err)
c.EventRecorder.Event(binding, corev1.EventTypeWarning, events.EventReasonSyncWorkFailed, err.Error())
c.EventRecorder.Event(workload, corev1.EventTypeWarning, events.EventReasonSyncWorkFailed, err.Error())
errs = append(errs, err)
} else {
msg := fmt.Sprintf("Sync work of resourceBinding(%s/%s) successful.", binding.Namespace, binding.Name)
klog.V(4).Infof(msg)
c.EventRecorder.Event(binding, corev1.EventTypeNormal, events.EventReasonSyncWorkSucceed, msg)
c.EventRecorder.Event(workload, corev1.EventTypeNormal, events.EventReasonSyncWorkSucceed, msg)
}
if err = helper.AggregateResourceBindingWorkStatus(c.Client, binding, workload, c.EventRecorder); err != nil {
klog.Errorf("Failed to aggregate workStatuses to resourceBinding(%s/%s). Error: %v.",
binding.GetNamespace(), binding.GetName(), err)
errs = append(errs, err)
}
if len(errs) > 0 {
return controllerruntime.Result{Requeue: true}, errors.NewAggregate(errs)
}
err = c.updateResourceStatus(binding)
if err != nil {
return controllerruntime.Result{Requeue: true}, err
}
return controllerruntime.Result{}, nil
}
execution controller¶
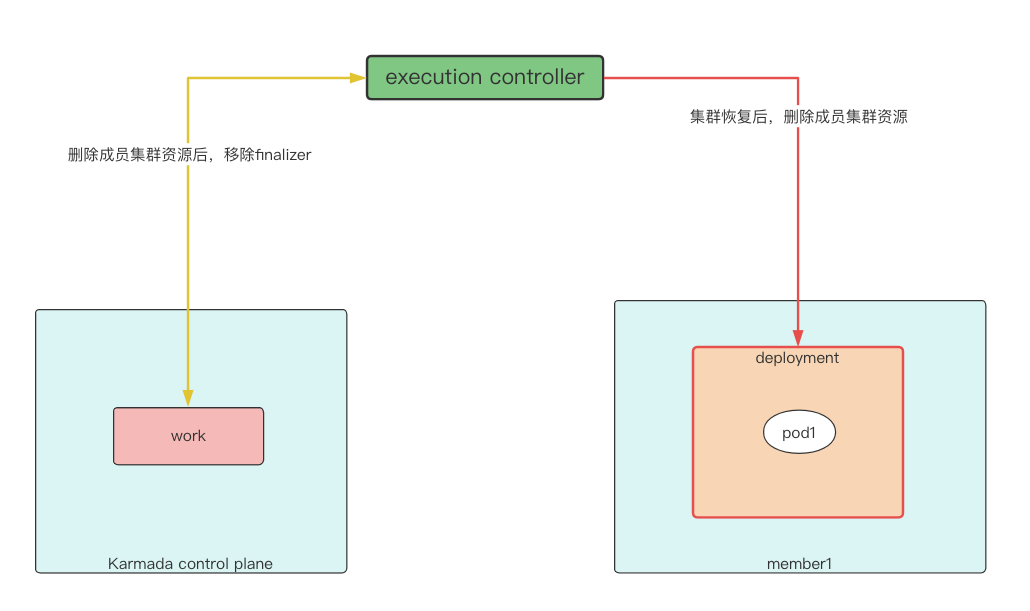
execution controller 的能力是 将成员集群对应执行命名空间的 work 中存放的实际需要下发的资源在对应成员集群创建、更新或删除。 所以,它的执行逻辑是和 work 的状态和集群的状态是息息相关的。如果 work 的 DeletionTimestamp 不为空,也就是 work 已经被删除, 则会继续判断集群状态,如果集群状态为 Ready,则会尝试删除成员集群上的资源。示例中,当集群发生故障后,资源转移到集群 member2 上所有副本都 Ready ,此时 gracefulEviction controller 会移除集群 member1 优雅驱逐任务,binding controller 认为 member1 上的 work 是孤儿,所以会删除 work。此时集群 member1 执行命名空间下的 work DeletionTimestamp 不为空, 同时集群 Not Ready,所以会进入 cluster.DeletionTimestamp.IsZero() 的判断分支,从而重新入队列,work finalizer 不会被移除,所以示例中 work 一直存在。当集群恢复后,则会进入 util.IsClusterReady(&cluster.Status) 分支, 此时会尝试删除成员集群上 work 对应的资源,删除成功后,执行 removeFinalizer,将 work 上的 finalizer 移除, 这样 work 就会被删除。所以示例中集群恢复后,集群 member1 执行命名空间下的 work 和成员集群上的 deployment 都被移除了。
if !work.DeletionTimestamp.IsZero() {
// Abort deleting workload if cluster is unready when unjoining cluster, otherwise the unjoin process will be failed.
if util.IsClusterReady(&cluster.Status) {
err := c.tryDeleteWorkload(clusterName, work)
if err != nil {
klog.Errorf("Failed to delete work %v, namespace is %v, err is %v", work.Name, work.Namespace, err)
return controllerruntime.Result{Requeue: true}, err
}
} else if cluster.DeletionTimestamp.IsZero() { // cluster is unready, but not terminating
return controllerruntime.Result{Requeue: true}, fmt.Errorf("cluster(%s) not ready", cluster.Name)
}
return c.removeFinalizer(work)
}
以上就是 Karmada 实现故障恢复的原理,从中可以看出,它是**由多个控制器和调度器协同完成的** 。 如果其中一个控制器或调度器出问题,那么都会影响故障恢复的功能。笔者曾经提过一个故障转移不符合预期的 issue 2769, 最终发现是由于资源状态计算错误引起的,详细的修改见 pull request 2928。这就是由于在故障转移过程中, 开启了优雅驱逐,优雅驱逐会获取调度目标集群上的资源健康状态,计算是否都是 Healthy,如果都是 Healthy 则会移除优雅驱逐任务,但是由于状态计算错误,导致实际转移的目标集群上资源都是 Healthy,但是优雅驱逐控制器计算为 Healthy,所以导致优雅驱逐任务一直保留,从而出现 issue 中问题。再如 issue 2989 中,提到 work 状态仍然为 Healthy,这是由于成员集群状态为 Not Ready,从而导致 execution controller 在更新 work 状态前就重新入队列, 所以 work 状态中仍然是正确的,但是此时 work 的 DeletionTimestamp 不为空。
总结¶
当前版本的 Karmada 可以实现副本拆分策略和全量策略,但是在真正的业务场景中,例如有状态应用如何实现故障转移? 转移后如何保证应用的网络和存储?这个有待进一步实际操作验证,需要根据实际情况具体问题具体分析。
同时,笔者在同客户交流过程中,有客户提到,集群故障恢复后,是否可以进行重调度,将副本调度回到恢复的集群。 目前,在参与社区会议中提到这一点,目前社区的方向是,将来可能会提供给客户选择是否重调度的能力。 也就是说,将来的 Karmada 版本**可能会支持用户自定义是否要调度回恢复的集群** 。 目前没有调度回原集群的原因是,考虑到重调度对应用稳定性的影响。 同时,目前在最新的社区会议中,有讨论 增强 Failover 的 feature,会在传播策略中增加 Failover 更多配置能力 , 具体的讨论这里就不展开了,我们一起期待。
综上所述,基于 Karmada 应用可以实现集群级别的高可用。 随时多云的发展,Karmada 被越来越多的人所使用,我们相信,Karmada 会在越来越多的场景中解决实际问题。 在笔者参与贡献的 CNCF 项目贡献中,目前,Karmada 是 issue 回复最快,代码合并请求处理最快的项目, 这得益于社区主导者良好的代码贡献管理机制。所以,基于增长的使用用户, 社区快速的响应,我相信,Karmada 将会带给我们越来越多惊艳的能力。