Topology-Aware Scheduling: Smarter Scheduling for AI Workloads¶
Original article by AI Infrastructure Learning Path, published on November 25, 2025
Tags:#kubernetes #scheduling #topology #dra #device-plugin #gpu #nic
Why Topology? Why Now?¶
At KubeCon NA 2025, one theme dominated AI/ML discussions: Topology.
Everyone is talking about topology-aware scheduling because it is critical for optimizing AI workload performance.

Source: Lightning Talk: Mind the Topology - Roman Baron, NVIDIA
Modern AI workloads, especially distributed training and high-performance inference, are extremely sensitive to hardware topology. When GPUs, NICs, CPUs, and memory are not properly aligned within the same NUMA node, PCIe root, or network structure, performance can drop by 30–50% or more.
Background: Current Topology Scheduling Support¶
Device Plugin: Traditional Approach¶
Kubernetes Device Plugin has long been the standard mechanism for managing GPU and other hardware resources. Its API provides:
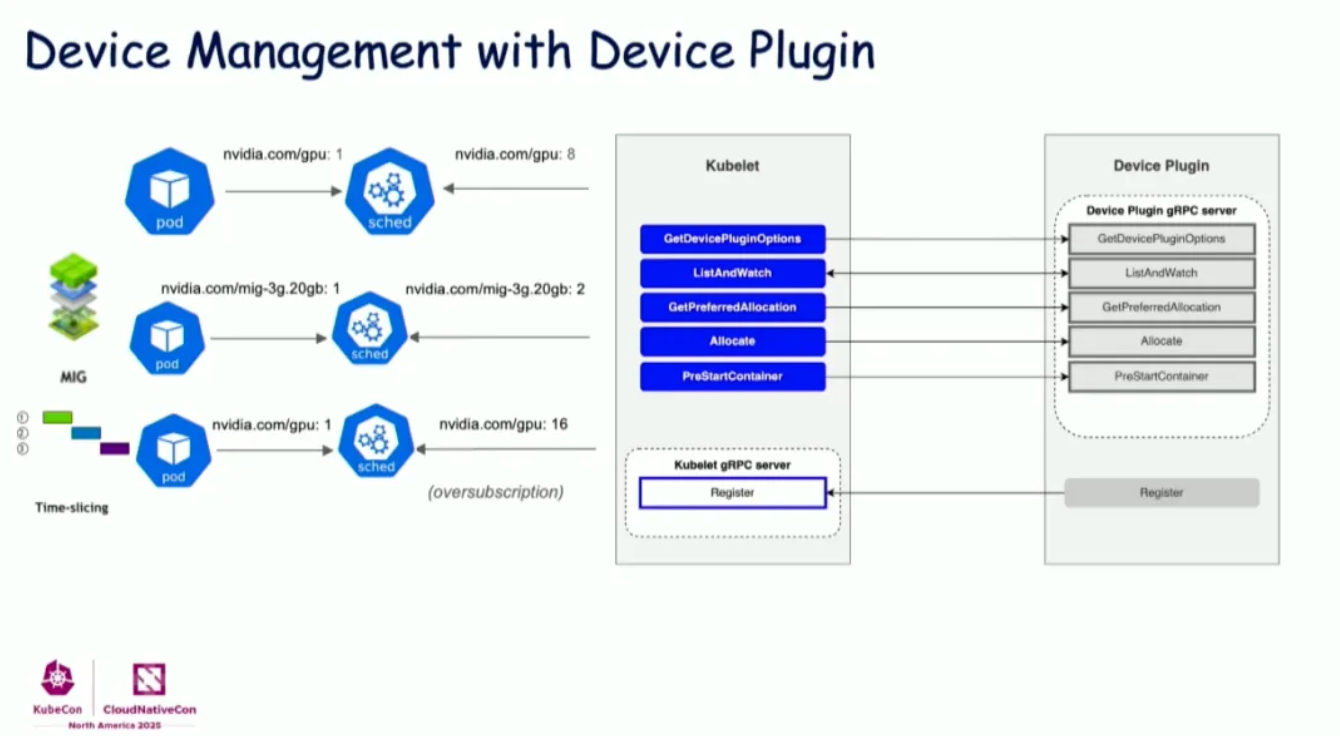
Source: KubeCon NA 2025: Device Management
Core components:
- GetDevicePluginOptions: Plugin configuration
- ListAndWatch: Reports available devices to kubelet
- GetPreferredAllocation: Suggests optimal device allocation (topology hints)
- Allocate: Allocates devices for containers
- PreStartContainer: Pre-start hook for containers
Device Plugin supports:
- Basic GPU counts (e.g.,
nvidia.com/gpu: 8) - MIG (Multi-Instance GPU) partitioning
- Time-slicing for GPU overcommit
Limitations of Device Plugin¶
However, Device Plugin has notable limitations for topology-aware scheduling:
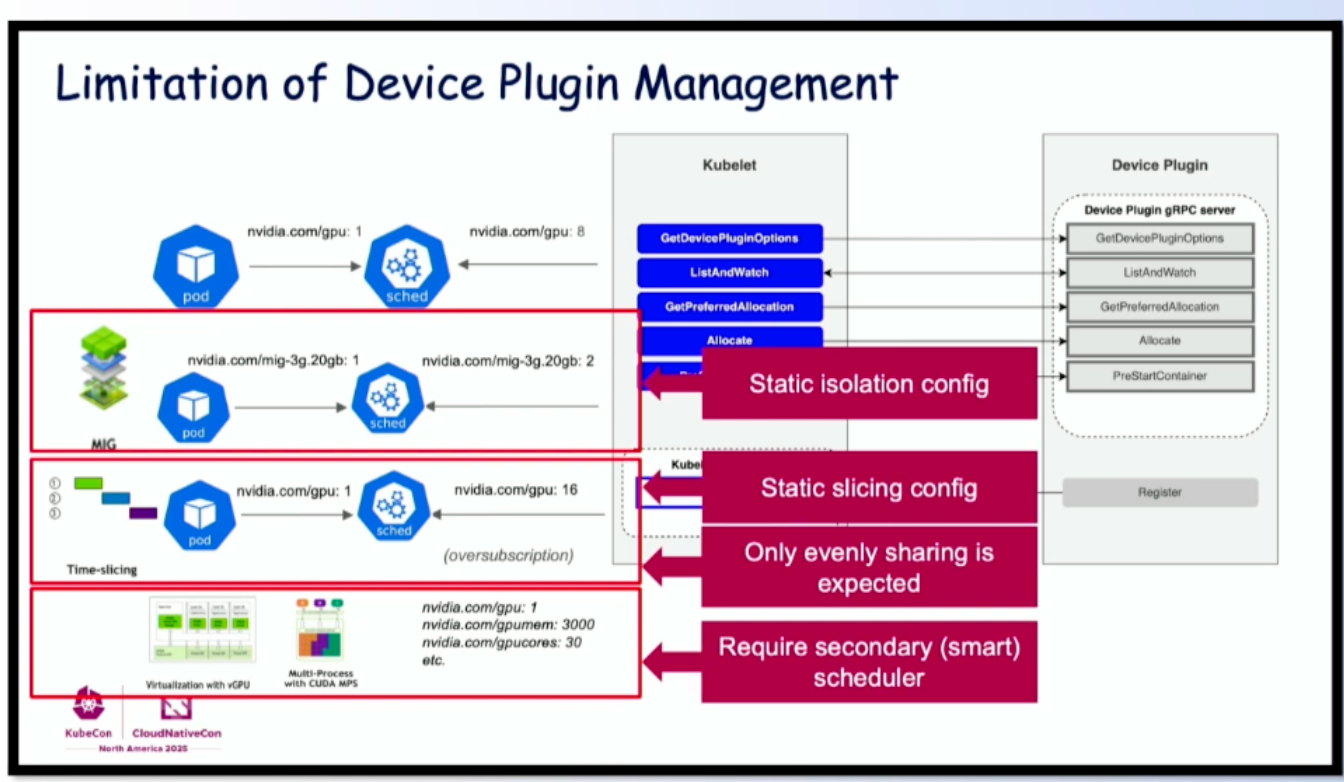
Source: KubeCon NA 2025: Device Management
- Static isolation configuration: MIG setup must be predefined
- Static time-slicing: Slice ratios fixed at deployment
- Uniform sharing only: Limited granularity
- Secondary schedulers required: Complex topologies need Volcano or Kueue
Kueue: Topology-Aware Scheduling¶
Kueue provides topology-aware scheduling using node labels. It uses hierarchical topology levels:
# Node labels for rack/block topology
cloud.google.com/gce-topology-block: "block-1"
cloud.google.com/gce-topology-subblock: "subblock-1"
cloud.google.com/gce-topology-host: "host-1"
kubernetes.io/hostname: "node-1"
````
Kueue supports:
* **Topology-aware scheduling:** Place Pods on nodes with matching topology
* **Cohort-based resource sharing:** Share resources within a topology group
* **Gang scheduling with topology:** Ensure all gang members are topology-aligned
Example ResourceFlavor configuration in Kueue:
```yaml
apiVersion: kueue.x-k8s.io/v1beta1
kind: ResourceFlavor
metadata:
name: gpu-topology
spec:
nodeLabels:
cloud.google.com/gce-topology-block: "block-1"
nodeTaints:
- effect: NoSchedule
key: nvidia.com/gpu
value: "present"
Volcano: Gang Scheduling with Topology¶
Volcano provides advanced scheduling features:
- Gang scheduling: All-or-nothing scheduling for distributed workloads
- Topology plugin: Considers GPU topology in decisions
- Network-aware scheduling: RDMA/InfiniBand topology awareness
Example PodGroup with topology policy:
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
metadata:
name: distributed-training
spec:
minMember: 8
minResources:
nvidia.com/gpu: "8"
queue: training-queue
# NVLink topology affinity
topologyPolicy: "best-effort"
DRA: Next-Generation Topology Management¶
Dynamic Resource Allocation (DRA) represents a fundamental shift in how Kubernetes handles device topology. DRA provides structured parameters to express rich topology constraints.
How DRA Handles Topology-Aware Scheduling¶
DRA uses attributes and constraints with CEL (Common Expression Language) to express topology requirements. Key mechanisms:
-
Device attributes: Each device publishes topology info
pcieRoot: PCIe hierarchy identifiernumaNode: NUMA node associationnvlinkDomain: NVLink domainrdmaDevice: Associated RDMA NIC
-
Constraints: CEL expressions enforce topology rules
- GPUs and NICs on the same PCIe root
- CPU and memory on the same NUMA node
- NVLink connectivity between GPUs
-
SharedID: Devices in the same topology domain get shared identifiers
GPU + NIC Topology Coordination¶
DRA excels at coordinating GPU and NIC allocation on the same PCIe root, critical for GPU-Direct RDMA-based distributed training.
Example ResourceClaimTemplate with PCIe topology constraint:
apiVersion: resource.k8s.io/v1beta1
kind: ResourceClaimTemplate
metadata:
name: gpu-nic-topology
spec:
spec:
devices:
requests:
- name: gpu
deviceClassName: nvidia-gpu
count: 1
- name: rdma-nic
deviceClassName: rdma-nic
count: 1
constraints:
# GPU and NIC must share the same PCIe root
- requests: ["gpu", "rdma-nic"]
matchAttribute: pcieRoot
Workflow:
- DRA scheduler evaluates available GPUs and NICs
- For each candidate GPU, it finds NICs on the same PCIe root
- Only allocations satisfying constraints are considered
matchAttribute: pcieRootensures shared PCIe topology
DRANET: Network Device DRA¶
DRANET is Google’s implementation for network devices. It integrates node labels with Kueue topology-aware scheduling:
# Labels used by DRANET
cloud.google.com/gce-topology-block
cloud.google.com/gce-topology-subblock
cloud.google.com/gce-topology-host
kubernetes.io/hostname
DRANET + NVIDIA GPU DRA enables:
- RDMA NICs allocated with GPUs on the same PCIe root
- Multi-NIC distributed training configurations
- Network isolation with SR-IOV VFs
CPU Micro-Topology Support¶
dra-driver-cpu adds CPU micro-topology features:
- NUMA-aware CPU allocation
- Topology-aligned CPU pinning
- Coordination with GPU NUMA placement
DRAConsumableCapacity: New in Kubernetes 1.34¶
DRA introduces DRAConsumableCapacity, enhancing resource sharing while maintaining topology awareness.

Source: KubeCon NA 2025: Device Management
Key capabilities:
- Alpha feature introduced in Kubernetes 1.34
- Recommended for use starting Kubernetes 1.35 (still Alpha)
Core abilities:
- Allow multiple allocations: Across multiple resource requests
- Consumable capacity: Guarantees shared resources
Potential use cases:
- Virtual GPU memory partitioning
- Shared virtual NICs (vNICs)
- Bandwidth-limited network allocation
- I/O bandwidth sharing on smart storage devices
- Native CPU resource requests
Challenges: Migrating from Device Plugin to DRA¶
Organizations heavily invested in Device Plugin face challenges when moving to DRA.
1. Existing Device Plugin Investment¶
Organizations may have:
- Custom Device Plugins with topology logic
- Integration with monitoring/observability tools
- Operator workflows dependent on Device Plugin API
2. Coexistence Issues¶
Running Device Plugin and DRA together can cause:
- Resource conflicts: Same device managed by both systems
- Topology mismatch: Different views of topology
- Scheduling confusion: Scheduler lacks unified view
3. Feature Gaps¶
Some Device Plugin features lack DRA equivalents:
- Device health monitoring
- Hot-plug support
- Prometheus metrics integration
Solutions and Workarounds¶
DRA extension capabilities:
- DRA drivers can provide a compatibility layer
- NVIDIA DRA driver supports migration from Device Plugin
- NRI integration can bridge runtime-level gaps
Recommended migration path:
- Deploy DRA alongside existing Device Plugin
- Use node taints to separate workloads
- Gradually migrate workloads to DRA-based resource claims
- Remove Device Plugin after all workloads are migrated
Related KubeCon Talks¶
Lightning Talk: Mind the Topology¶
Mind the Topology: Smarter Scheduling for AI Workloads on Kubernetes - Roman Baron, NVIDIA
Highlights:
- Why topology matters for AI workloads
- NVIDIA KAI Scheduler implementation
- NVIDIA KAI-Scheduler
Deep Dive: Device Management¶
DRA and Device Plugin Deep Dive
Highlights:
- Evolution from Device Plugin to DRA
- DRAConsumableCapacity feature
- Multi-device topology coordination
Topology-Aware Scheduling Best Practices¶
-
Understand your topology requirements
- Analyze workload sensitivity to topology
- Map hardware topology (PCIe, NUMA, NVLink, RDMA)
-
Choose the right scheduling approach
- Simple GPU workloads: Device Plugin + Topology Manager
- Complex multi-device workloads: DRA with constraints
- Distributed training: Kueue or Volcano + DRA
-
Label nodes with topology information
- Use a consistent labeling scheme
- Include rack, block, and host-level topology
-
Test topology impact
- Benchmark with and without topology alignment
- Measure latency and throughput differences
-
Plan migration
- Start new workloads on DRA
- Conduct compatibility testing
- Document topology requirements
Conclusion¶
Topology-aware scheduling has evolved from a nice-to-have to a critical requirement for AI workloads. The transition from Device Plugin to DRA represents a fundamental shift in Kubernetes device management:
- Device Plugin: Simple and mature, but limited topology support
- DRA: Rich topology expression, multi-device coordination, the future of Kubernetes device management
As AI workloads grow more complex, the demand for fine-grained topology-aware scheduling will only increase. Whether using Kueue, Volcano, or native Kubernetes scheduling, understanding topology and planning DRA adoption is essential for optimizing AI infrastructure.
Resources¶
Projects¶
- DRA - Dynamic Resource Allocation
- NVIDIA DRA GPU Driver
- NVIDIA KAI Scheduler
- Kueue
- Volcano
- DRANET
- dra-driver-cpu