Optimizing Failover Delay Sensitivity¶
Multicloud support enables cross-cluster automatic failover for applications, thereby ensuring the stability of applications deployed across multiple clusters. The delay sensitivity of failover is mainly influenced by the following two dimensions of metrics, which need to be configured in combination to achieve the desired delay sensitivity effect.
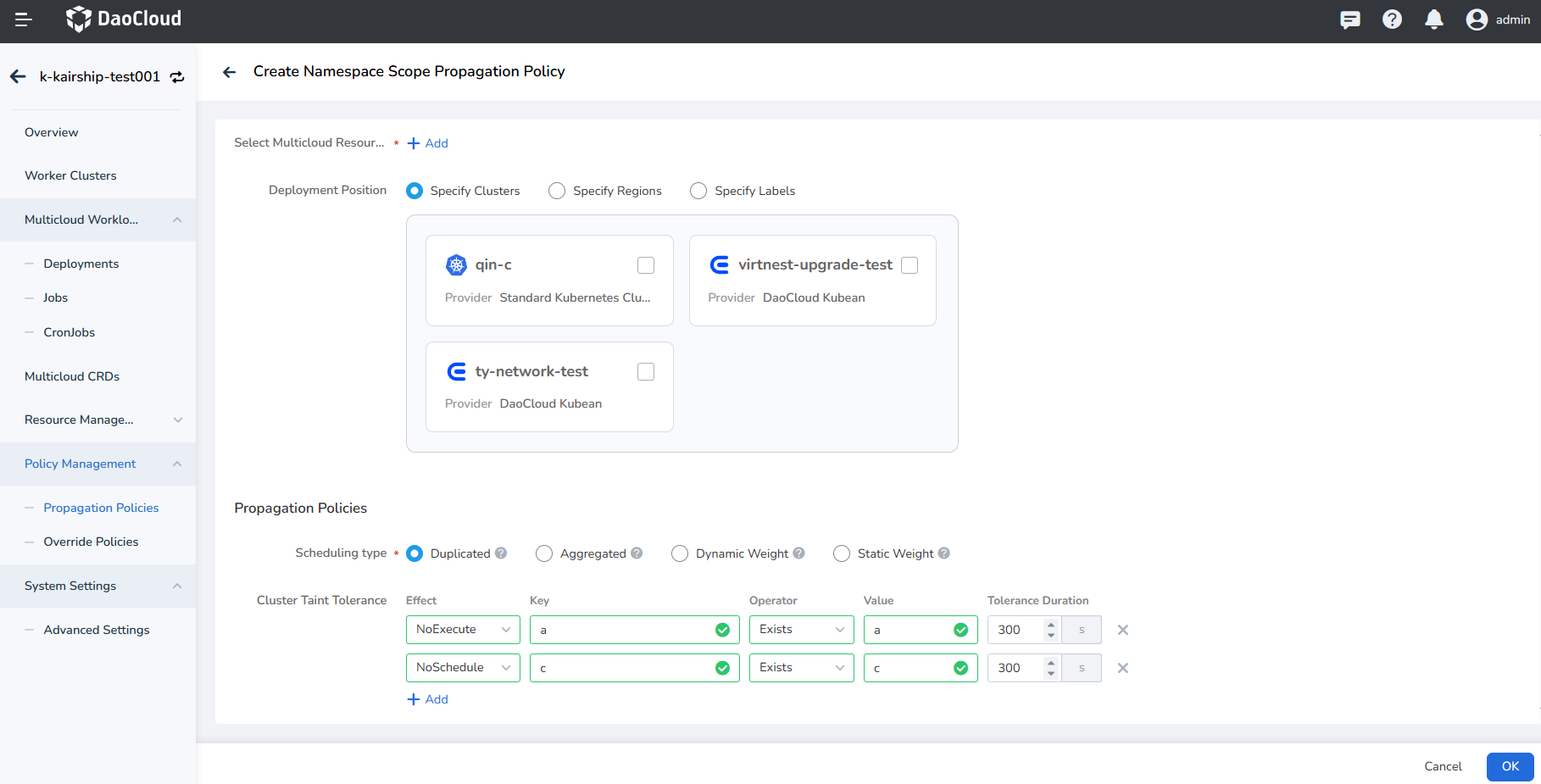
- Cluster Dimension: Duration for marking a cluster as unhealthy, Cluster eviction tolerance duration
- Workload Dimension: Cluster taint tolerance duration
Introduction to Failover Features¶
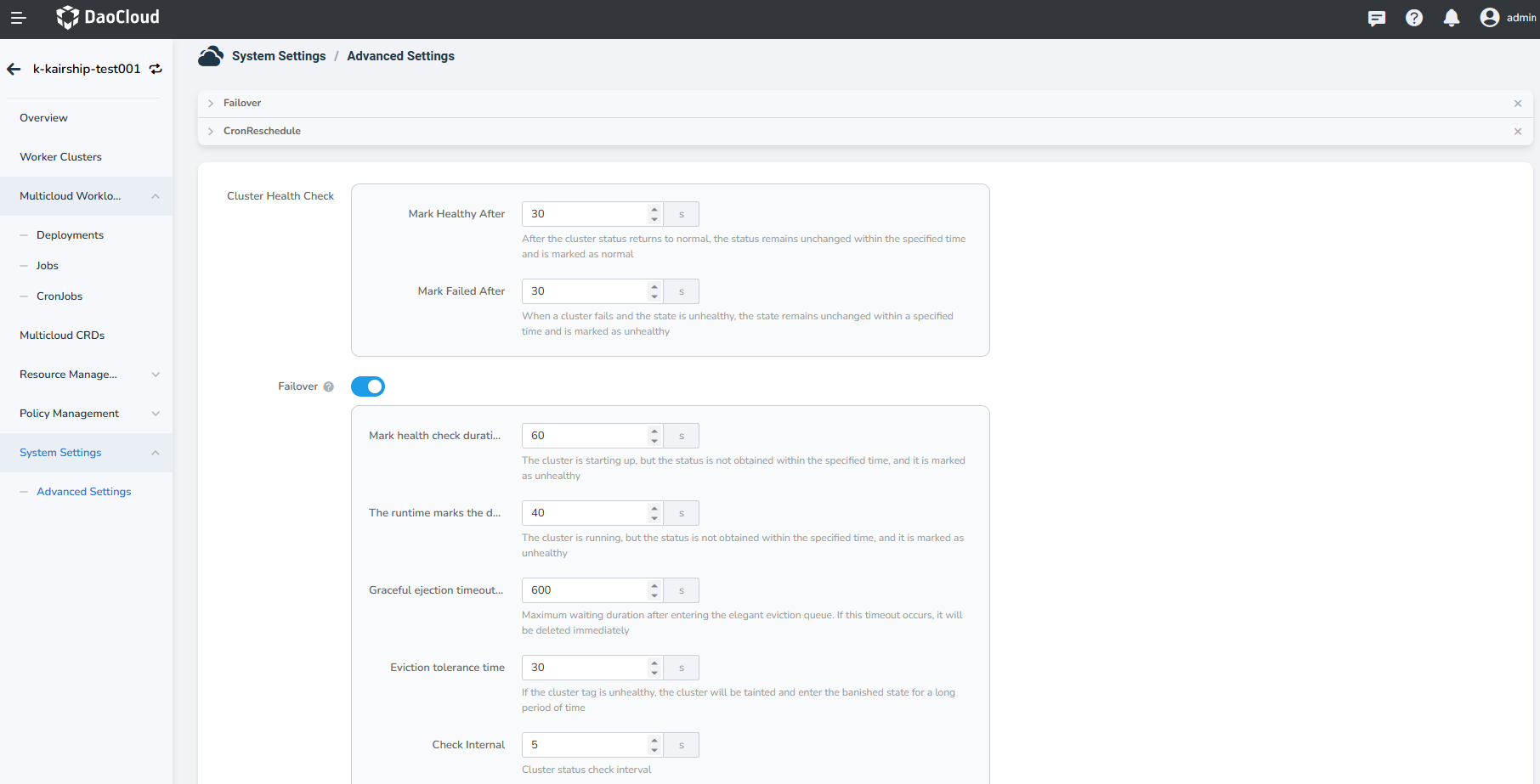
After enabling failover in DCE 5.0 Multicloud Management, the following configuration options are provided:
| Parameter | Description | Field Name | Default Value |
|---|---|---|---|
| ClusterMonitorPeriod | Interval for checking cluster status | Mark health check duration at startup | 60s |
| ClusterMonitorGracePeriod | If the cluster health status is not obtained within this configured time during runtime, the cluster will be marked as unhealthy | The runtime marks the duration of an unhealthy check | 40s |
| ClusterStartupGracePeriod | If the cluster health status is not obtained within this configured time at startup, the cluster will be marked as unhealthy | Graceful ejection timeout duration | 600s |
| FailoverEvictionTimeout | After a cluster is marked as unhealthy, it will be tainted and enter eviction state if this duration is exceeded (cluster will be tainted with eviction) | Eviction tolerance time | 30s |
| ClusterTaintEvictionRetryFrequency | Maximum waiting duration after entering the graceful eviction queue, after which immediate deletion will occur | Check Interval | 5s |
Timeline for Workload Eviction¶
A simple explanation of the diagram below: We stipulate that the cluster API is called every 10 seconds to record the health status of the cluster. When all four results are healthy, we consider the cluster to be healthy. At this point, if the TCP connection between DCE and the cluster API server is disconnected for 10-20 seconds and the cluster health status is not obtained, the cluster will be considered abnormal. If the cluster does not recover health within the specified time, it will be marked as unhealthy and tainted with NoSchedule. If it exceeds the specified eviction tolerance duration, it will be tainted with NoExecute and eventually evicted.
Optimization Configuration for Multicloud Instances¶
In a multicloud instance, you need to enter the advanced settings -> failover section. The following configurations can refer to the above diagram to fill in parameter information.
Configuration Optimization for Multicloud Workloads¶
The configuration optimization for multicloud workloads is mainly related to their propagation policy (PP). The proper cluster taint tolerance duration needs to be modified in the propagation policy.