创建 Elasticsearch 实例¶
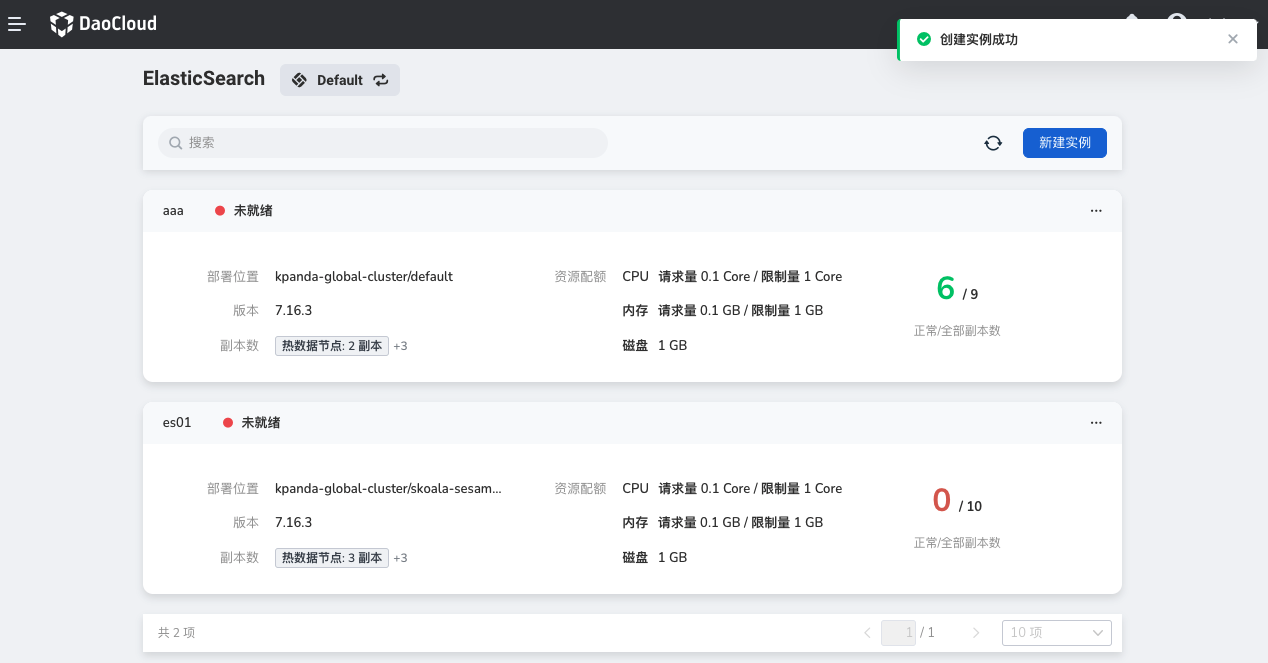
在 Elasticsearch 实例列表中,执行以下操作创建一个新的实例。
-
在 Elasticsearch 搜索服务的首页右上角点击 新建实例 。
-
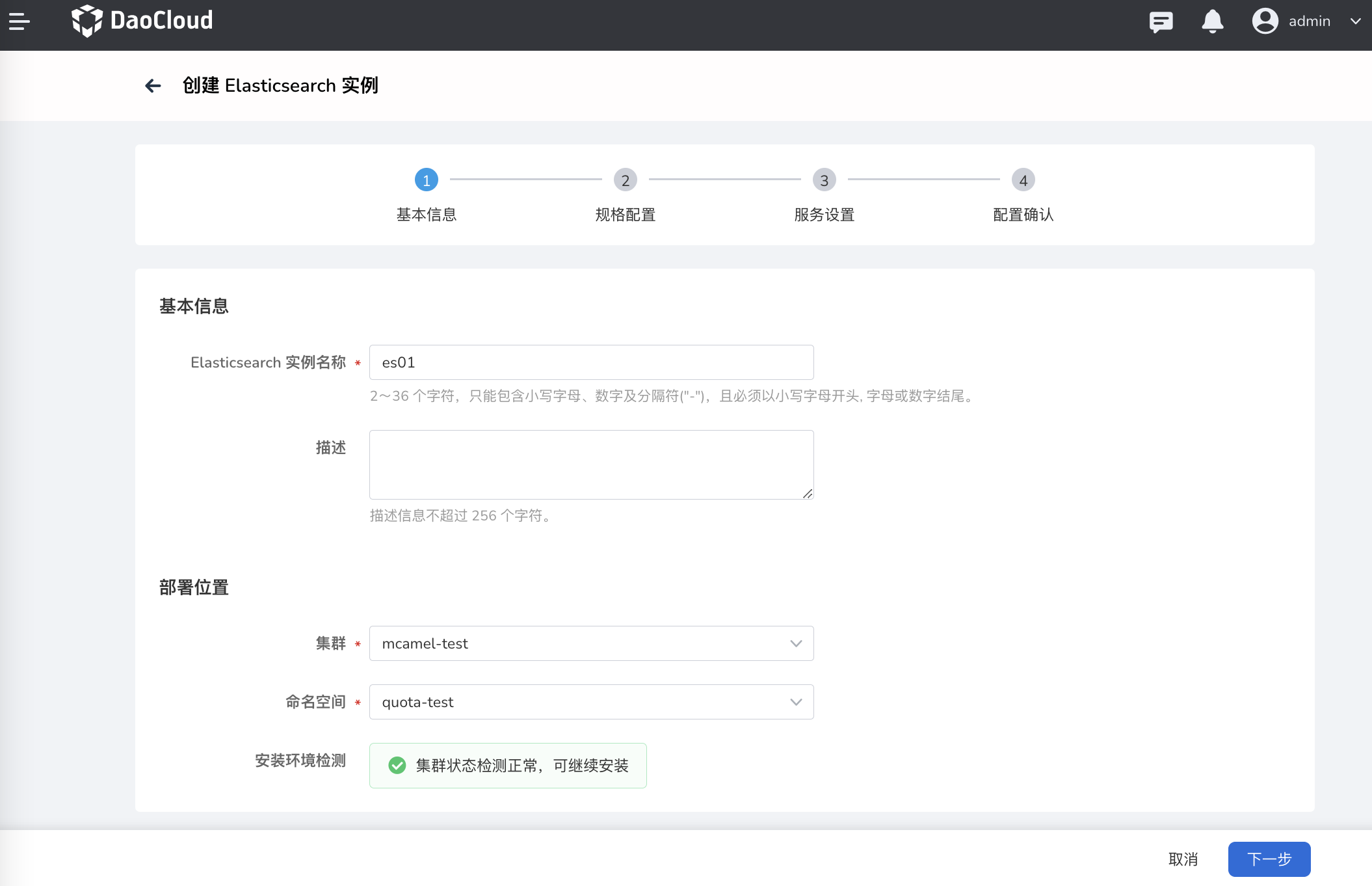
填写实例的 基本信息 。通过 安装环境检测 后,点击 下一步 。
如未通过安装环境检测,页面会给出失败原因和操作建议。常见原因是缺少相关组件,根据页面提示安装对应的组件即可。
-
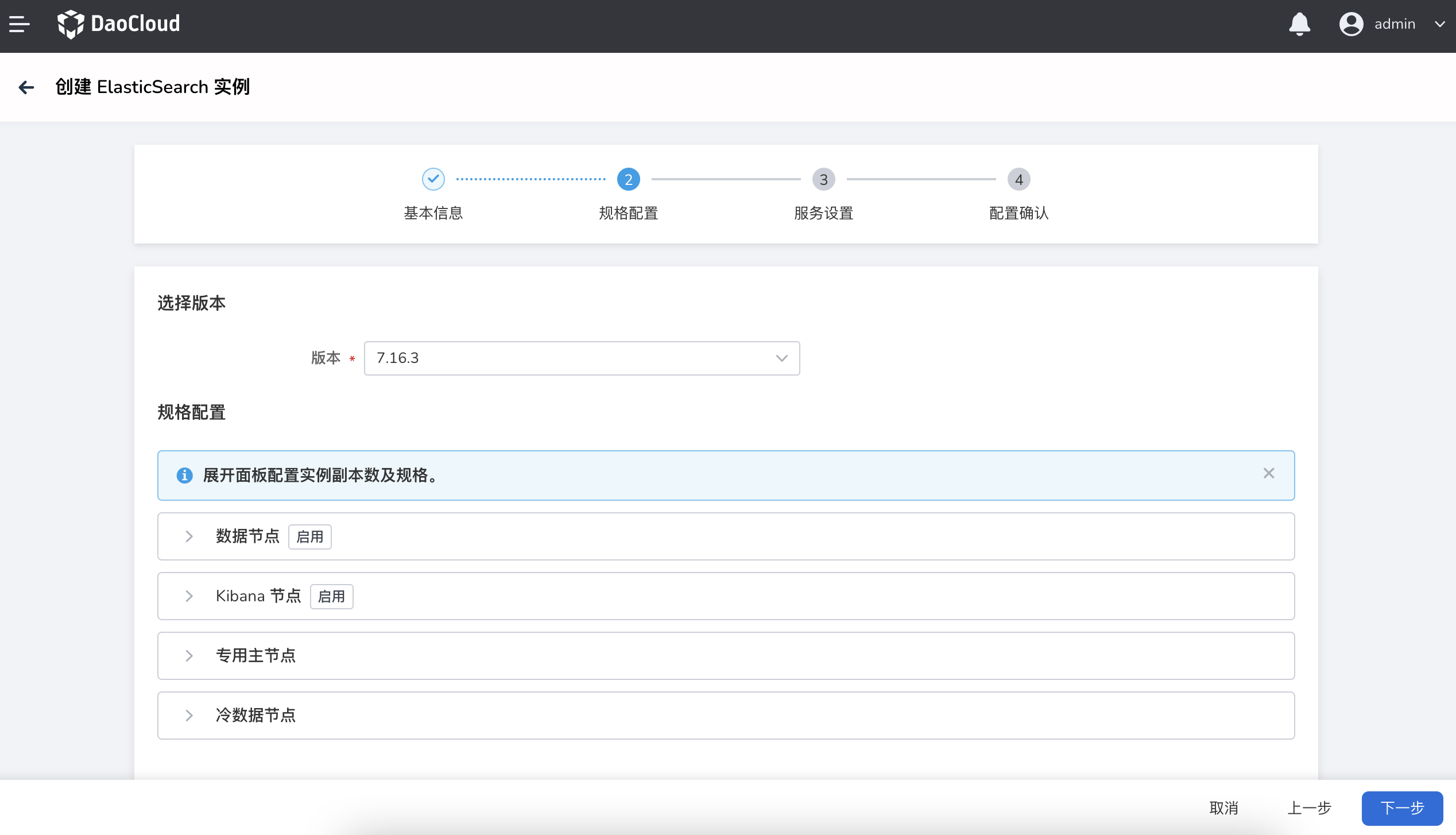
选择版本:选择基于哪个 Elasticsearch 版本创建实例,目前仅支持 7.16.3
-
参考以下信息填写实例的 规格配置 。
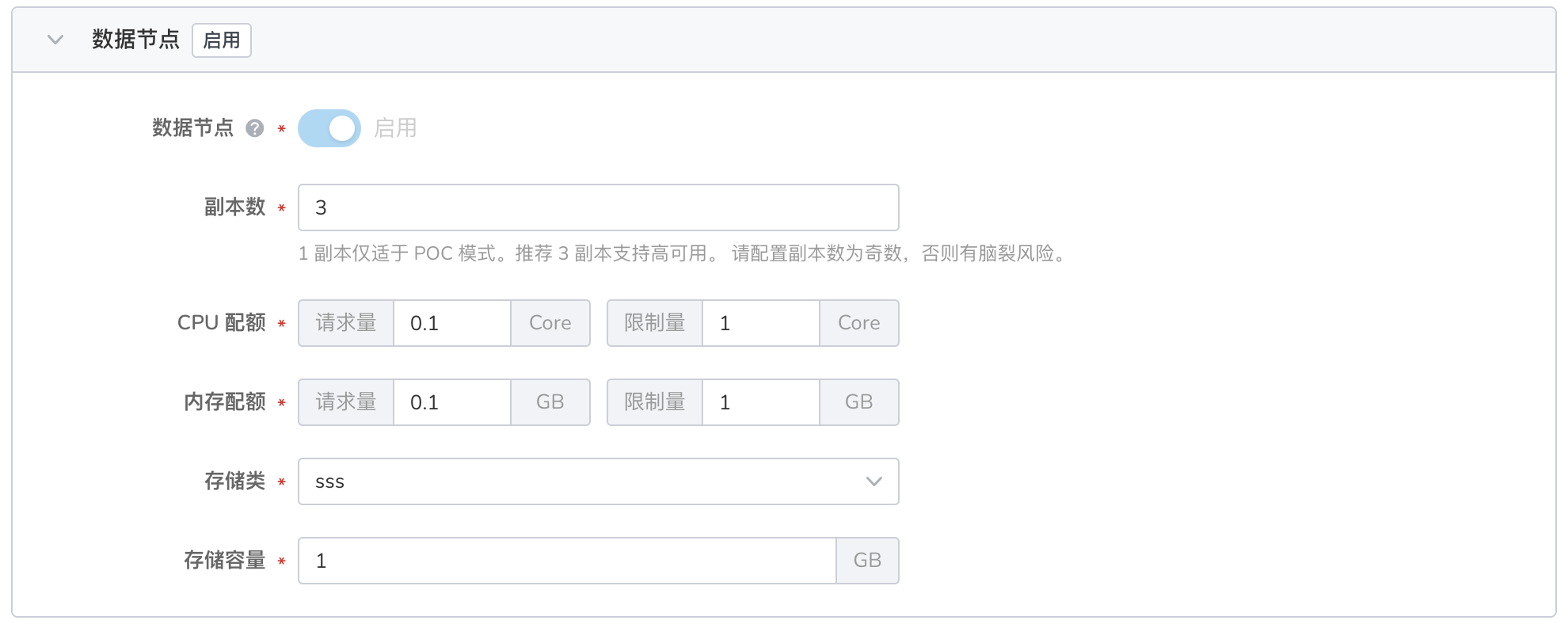
- 用于存储数据,执行增删改查、搜索、聚合等数据相关操作。数据节点对资源要求较高,需要配置充足的资源。
- 如果未启用 专用主节点 ,由 数据节点 充当`专用主节点。
- 最少 1 副本,最多 50 个副本,默认 3 副本。
- 副本数建议为奇数,否则存在脑裂风险。
- Kibana 是适用于 Elasticsearch 的可视化分析平台,可搜索、查看存储在索引中的数据并与其进行交互。
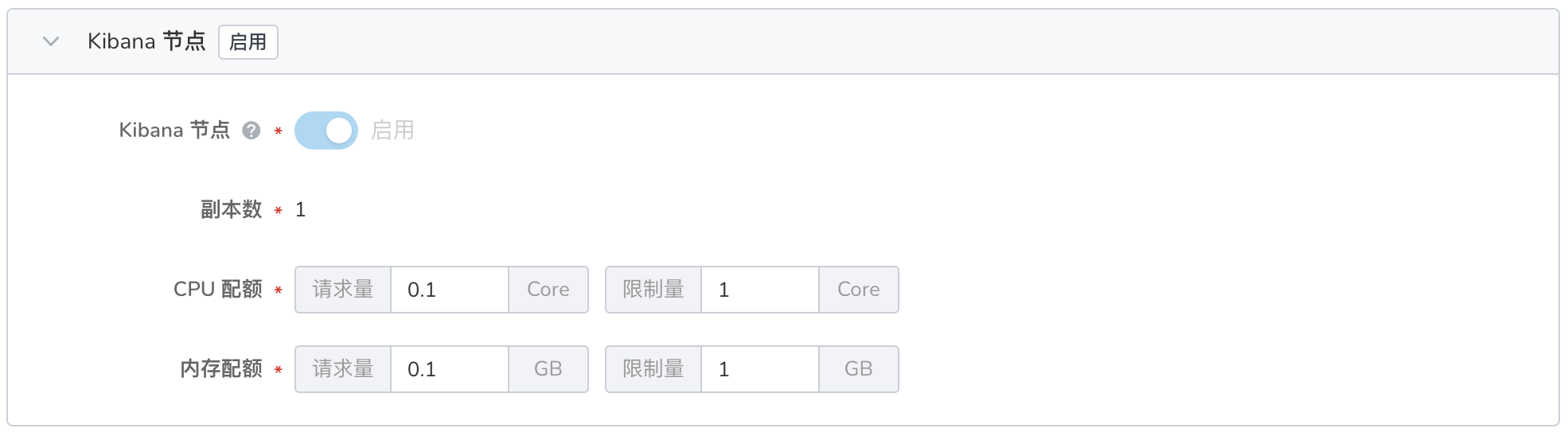
- 默认启用 Kibana 节点 ,用于存放 Elasticsearch 可视化数据的节点。
- 默认为 1 副本,不可修改。
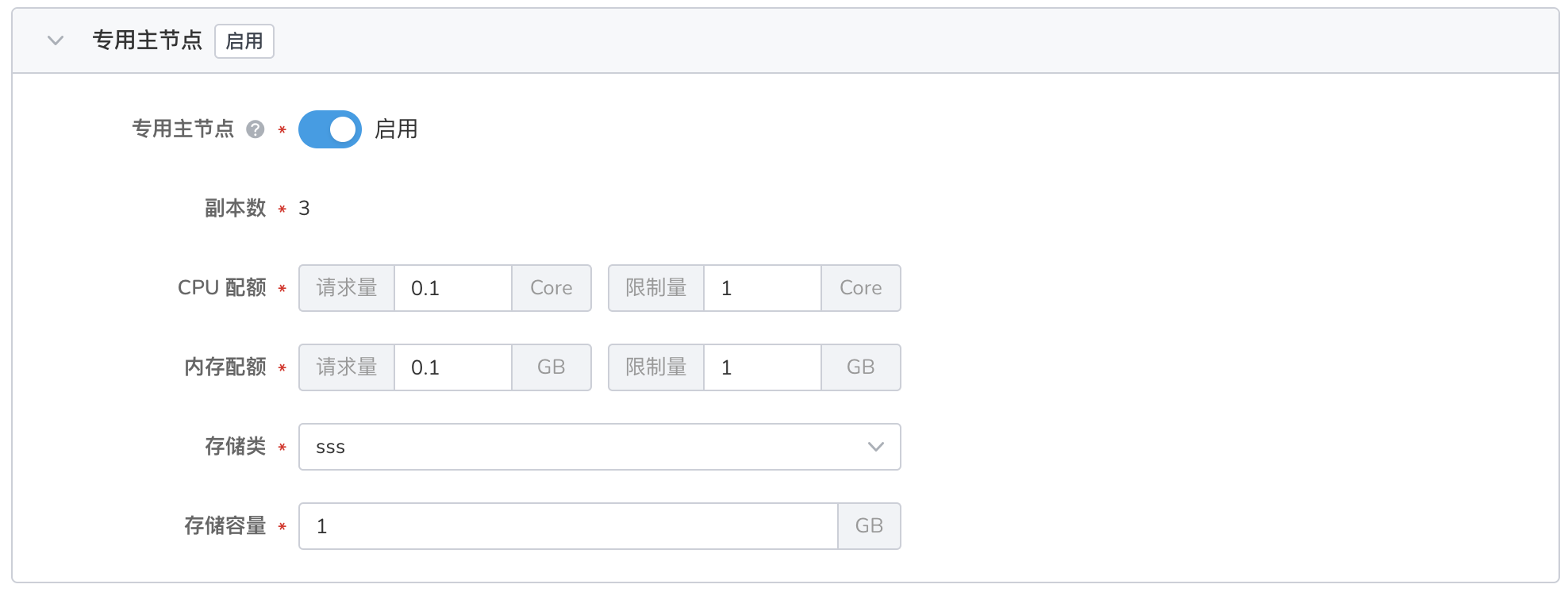
- 主节点负责集群范围内的轻量化操作,例如创建/删除索引、监听其他类型节点的状态、决定如何分配数据分片等。
- 如果不启用 专用主节点 ,则由数据节点充当主节点。这样可能会存在数据节点和主节点竞争资源的情况,影响系统稳定性。
- 启用 专用主节点 后,主节点与 数据节点 分离,有利于保障服务的稳定性。
- 默认 3 个副本,不可修改。
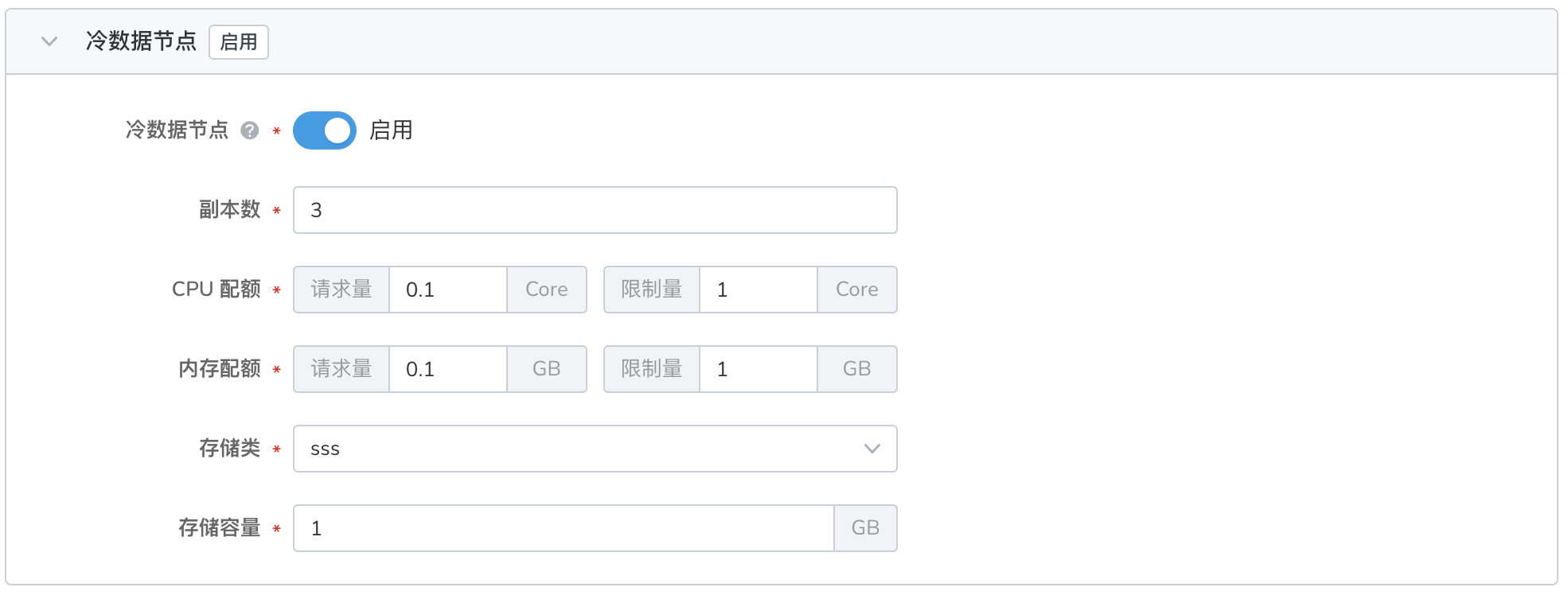
- 存储历史数据等查询频率低且基本无需写入的数据。
- 最少 2 副本,最多 50 副本,默认 3 副本。
- 如果业务中同时存在“查询频率高/写入压力大“和”查询频率/低基本无写入“的数据,建议启用 冷数据节点 ,实现冷热数据分离。
- 启用 冷数据节点 后,会自动开启 专用主节点 。
-
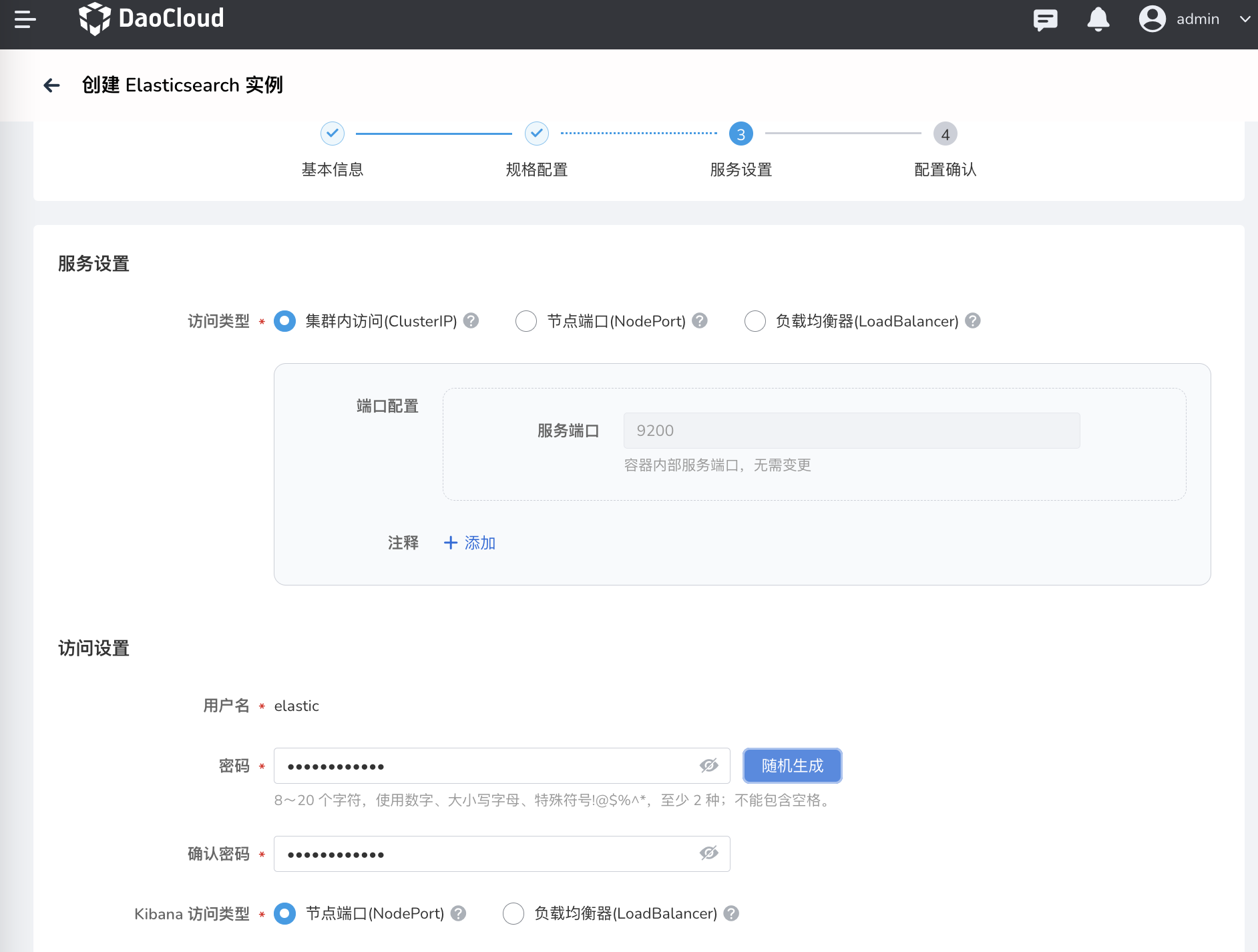
参考以下说明填写 服务设置
- 访问类型:Elasticsearch 实例对应的 Service 的类型。有关各种类型的详细说明,可参考服务类型
- 访问设置:访问 Elasticsearch 实例的用户名和密码,以及 Kibana 的访问类型。
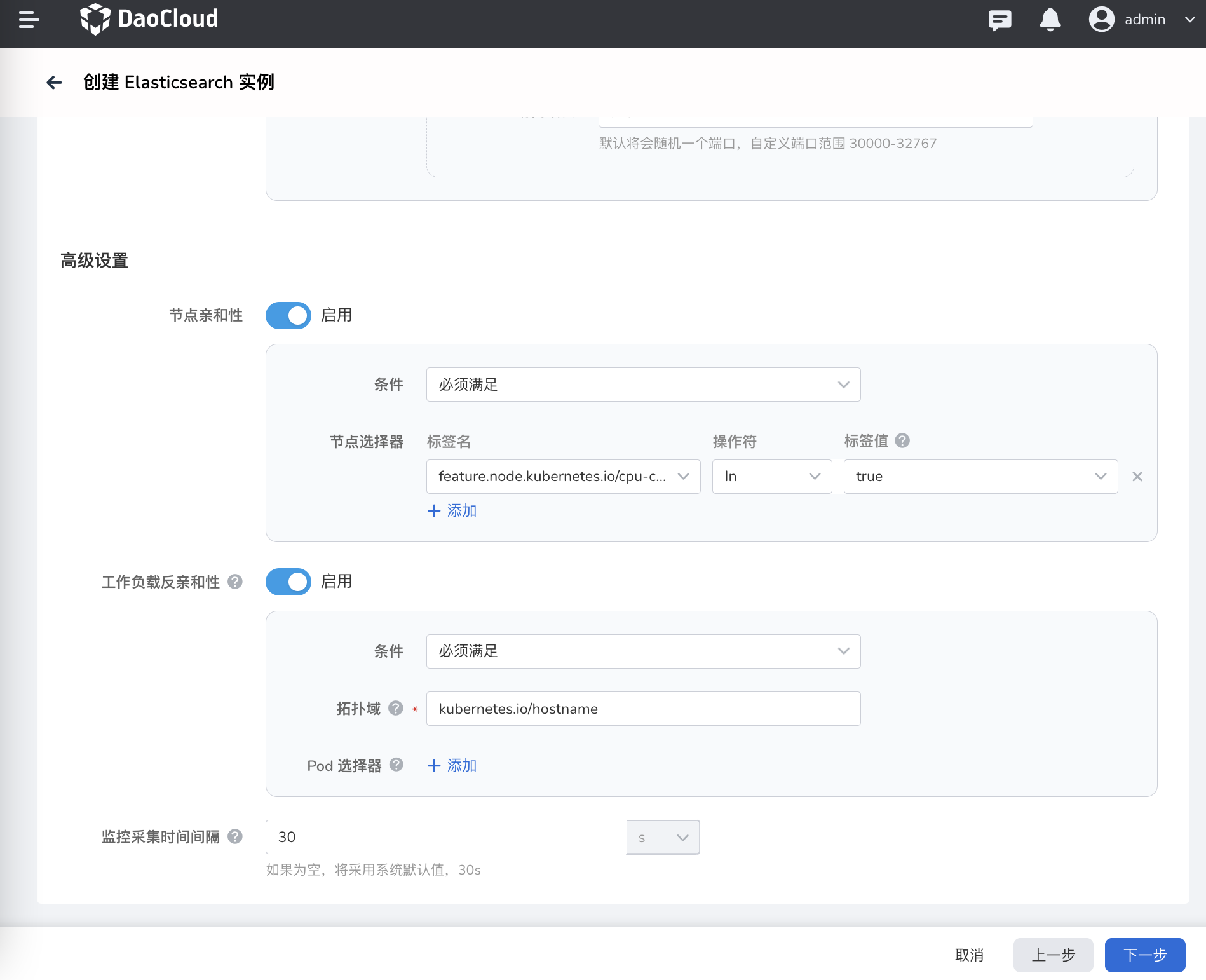
- 节点亲和性:启用后,只能/尽量将 Elasticsearch 实例调度到带有特定标签的节点上。
- 工作负载亲和性:在拓扑域(反亲和性的作用范围)内,根据反亲和性将工作负载下的 Pod 分发到多个节点中,避免多个 Pod 被集中调度到某一个节点,造成节点过载。相关的视频教程可参考工作负载反亲和性
- 监控采集时间间隔:实例监控的数据采集时间间隔。如果不设置,将采用全局设置。默认为 30s。
-
检查所填信息,确认无误后点击 确定 。如需修改可点击 上一步 返回修改配置。
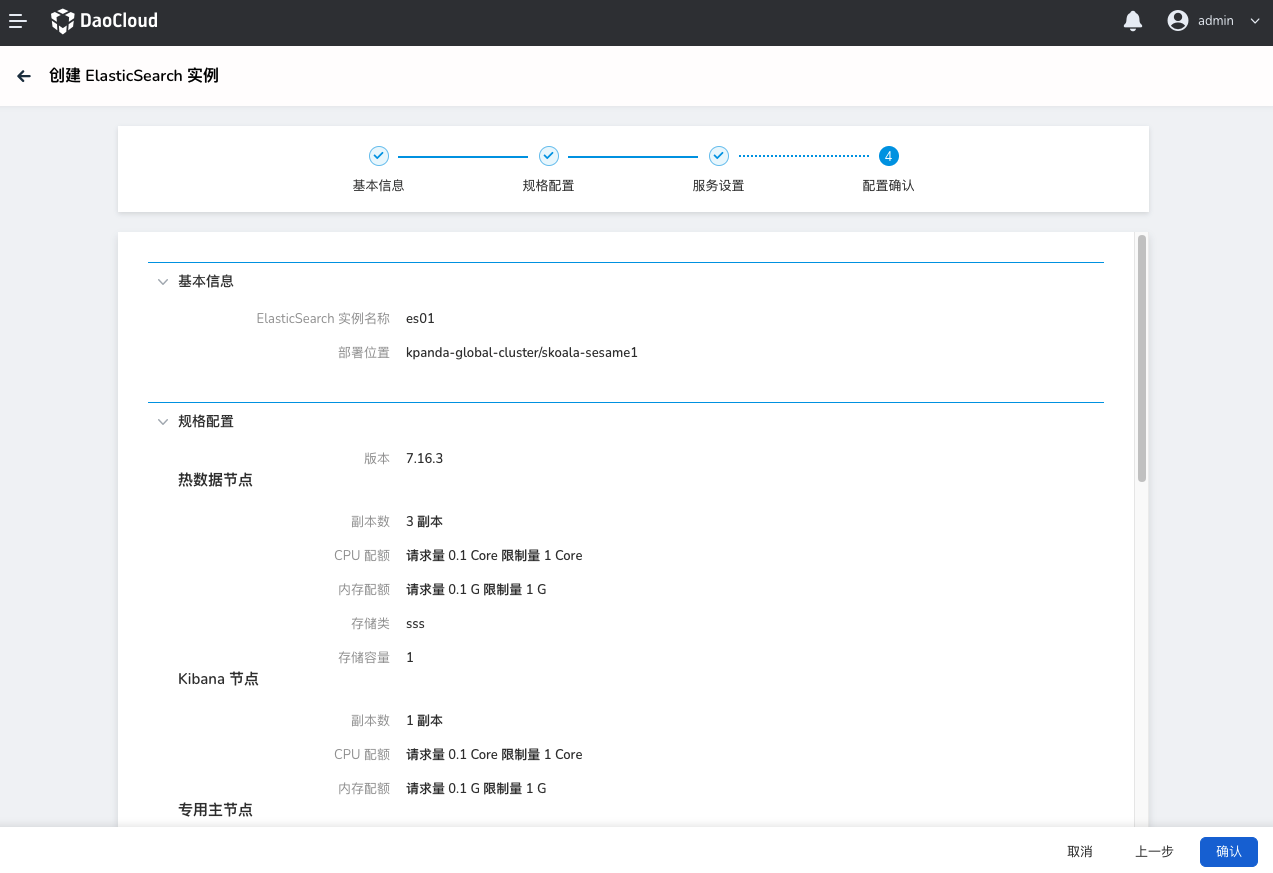
实例创建成功后,页面会自动跳转到 Elasticsearch 实例列表,可查看所有实例的基本信息和状态。