GPU 资源动态调节¶
提供 GPU 资源动态调整功能,允许您在无需重新加载、重置或重启整个运行环境的情况下,对已经分配的 vGPU 资源进行实时、动态的调整。 这一功能旨在最大程度地减少对业务运行的影响,确保您的业务能够持续稳定地运行,同时根据实际需求灵活调整 GPU 资源。
使用场景¶
- 弹性资源分配 :当业务需求或工作负载发生变化时,可以快速调整 GPU 资源以满足新的性能要求。
- 即时响应 :在面对突发的高负载或业务需求时,可以迅速增加 GPU 资源而无需中断业务运行,以确保服务的稳定性和性能。
操作步骤¶
以下是一个具体的操作示例,展示如何在不重启 vGPU Pod 的情况下动态调整 vGPU 的算力和显存资源:
创建一个 vGPU Pod¶
首先,我们使用以下 YAML 创建一个 vGPU Pod,其算力初始不限制,显存限制为 200Mb。
kind: Deployment
apiVersion: apps/v1
metadata:
name: gpu-burn-test
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: gpu-burn-test
template:
metadata:
creationTimestamp: null
labels:
app: gpu-burn-test
spec:
containers:
- name: container-1
image: docker.io/chrstnhntschl/gpu_burn:latest
command:
- sleep
- '100000'
resources:
limits:
cpu: 1m
memory: 1Gi
nvidia.com/gpucores: '0'
nvidia.com/gpumem: '200'
nvidia.com/vgpu: '1'
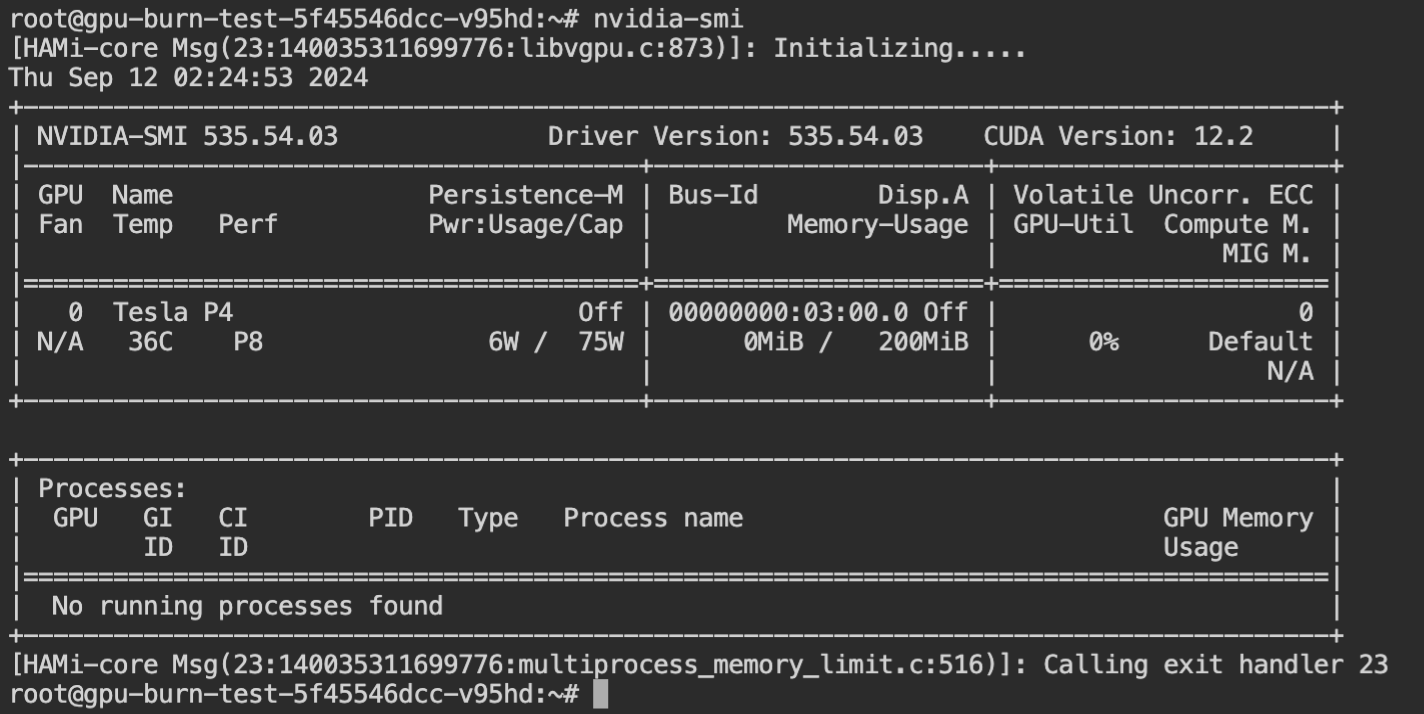
调整前查看 Pod 中的资源 GPU 分配资源:
动态调整算力¶
如果需要修改算力为 10%,可以按照以下步骤操作:
-
进入容器:
-
执行:
-
在当前终端直接运行:
程序即可生效。注意,不能退出当前 Bash 终端。
动态调整显存¶
如果需要修改显存为 300 MB,可以按照以下步骤操作:
-
进入容器:
-
执行以下命令来设置显存限制:
export CUDA_DEVICE_MEMORY_LIMIT_0=300m export CUDA_DEVICE_MEMORY_SHARED_CACHE=/usr/local/vgpu/d.cacheNote
每次修改显存大小时,
d.cache这个文件名字都需要修改,比如改为a.cache、1.cache等,以避免缓存冲突。 -
在当前终端直接运行:
程序即可生效。同样地,不能退出当前 Bash 终端。
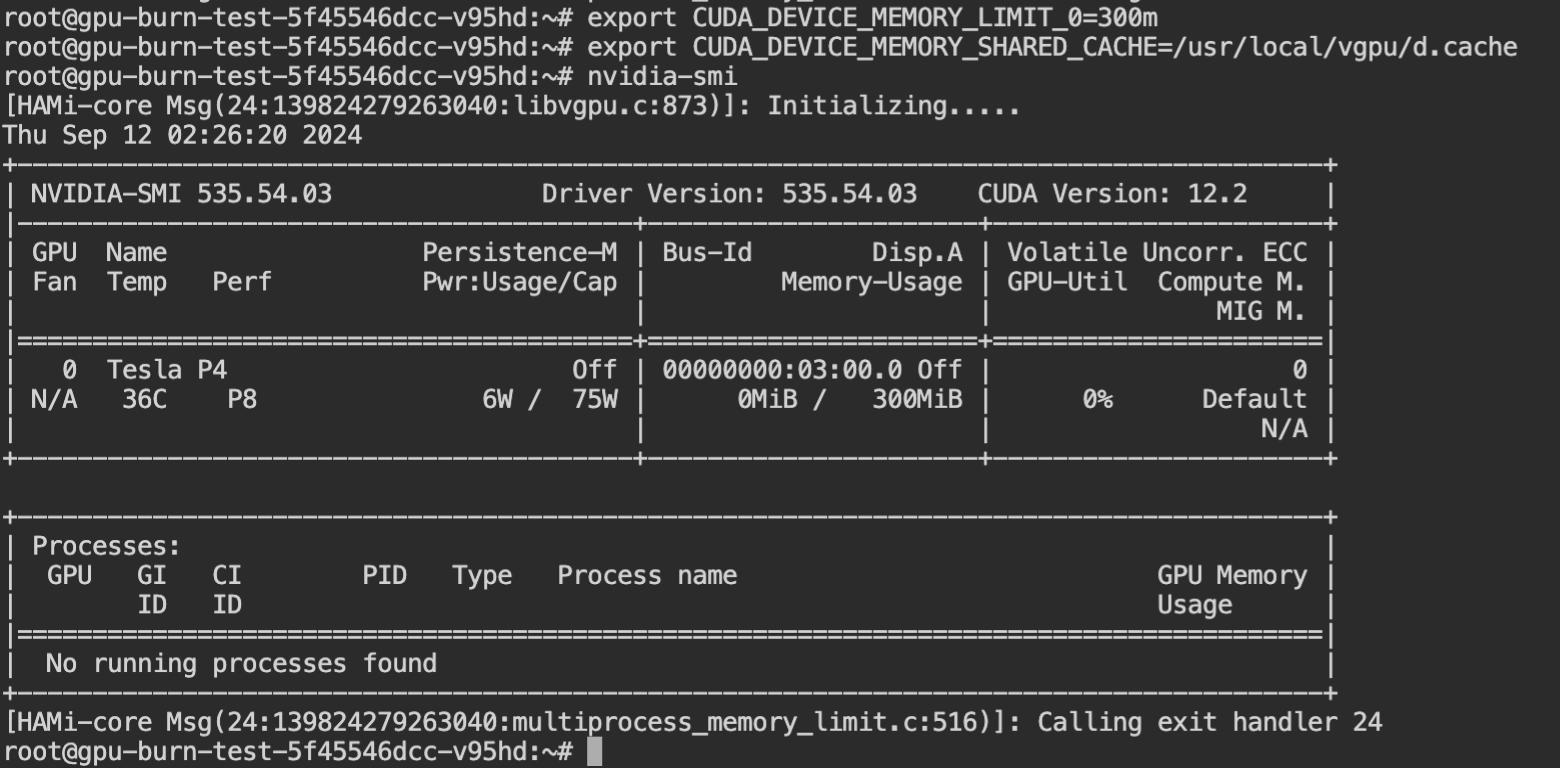
调整后查看 Pod 中的资源 GPU 分配资源:
通过上述步骤,您可以在不重启 vGPU Pod 的情况下动态地调整其算力和显存资源,从而更灵活地满足业务需求并优化资源利用。