安装指南¶
第一部分:Unifabric 核心组件安装¶
安装 Unifabric¶
前提条件¶
- Kubernetes 集群:确保您有一个正常运行的 Kubernetes 集群
- Helm 3.x:用于安装 Unifabric
- RDMA 网络环境:需要 RDMA 网络环境,支持 RoCE 协议
- 交换机 LLDP 支持:确保网络交换机已启用 LLDP 协议
推荐版本¶
| 组件 | 推荐版本 |
|---|---|
| Kubernetes | v1.22+ |
| Helm | v0.0.3+ |
安装步骤¶
如果需要使用 RDMA 邻居检测功能,请确保网络交换机已启用 LLDP 协议
-
节点标签配置
Unifabric Controller 只会运行在具有
unifabric.io/deploy=true的节点上,需要为运行 Unifabric Controller 的节点添加标签:Unifabric Agent 只应该运行在具有 RDMA 网络能力的节点上,而对于不支持 RDMA 网络能力的节点或虚拟机节点,我们应该为此类节点设置标签:
unifabric.io/deploy=false,禁止运行 Unifabric Agent。 -
添加 Helm 仓库
-
配置安装参数
helm upgrade --install unifabric unifabric/unifabric \ --namespace unifabric \ --create-namespace \ --set features.rdmaNeighbor.storageRdmaNicFilter="interface=ens2f0*"其中
storageRdmaNicFilter指定节点哪些 RDMA 网卡作为 RDMA 存储网卡。其他 RDMA 网卡作为 GPU 算力网络网卡,如果未配置本字段,则所有 RDMA 网卡都作为 GPU 算力网络网卡。 -
验证安装效果
-
检查 Pod 状态:
预期输出:
NAME READY STATUS RESTARTS AGE unifabric-746d4f8d75-qbknh 1/1 Running 0 2m unifabric-agent-4rpbw 2/2 Running 0 2m unifabric-agent-fgpkc 2/2 Running 0 2m注意:
unifabric-agentPod 包含两个容器:lldpd和unifabric-agent。 -
检查 FabricNode CRD 状态:
-
查看具体节点的邻居信息:
确认
status.computeNics和status.storageNics字段包含正确的 LLDP 邻居信息。 -
验证 ScaleoutGroup 自动分组功能,检查 ScaleoutLeafGroup CRD:
-
查看节点是否添加了 scaleoutleafgroup 的标签:
-
检查指标是否正常收集:
-
故障排查¶
参考故障排查
升级¶
升级 Unifabric 到新版本:
卸载¶
卸载 Unifabric:
如需完全清理,还需要删除 CRD 和命名空间:
监控和可视化¶
如果安装了 Grafana 仪表板,可以通过 DCE Insight 或直接访问 Grafana 来查看 Unifabric 的监控数据和网络拓扑可视化。
第二部分:交换机节点接入¶
功能描述¶
交换机节点接入(Switch Port Detail),可展示交换机端口的详细信息,包括端口状态、邻居设备信息等。该功能通过 gNMI 协议连接到交换机,获取端口状态和邻居设备信息,并将其存储在 Kubernetes 的 Custom Resource 中。
支持的交换机型号¶
目前支持云和交换机,未来会提供对英伟达某些型号交换机的支持。
字段说明¶
apiVersion: unifabric.io/v1beta1
kind: SwitchEndpoint
metadata:
name: gpu-leaf-switch-1
spec:
connection:
gnmi:
port: 8080
host: 10.193.77.201
group: gpu
manufacturer: cloudnix
status:
conditions:
- lastTransitionTime: "2025-08-19T00:05:57Z"
message: Successfully connected to SwitchEndpoint
reason: Connected
status: "True"
type: Connected
ports:
details:
- name: Ethernet0 # 端口名称
neighbor: # 描述该端口所连接的邻居设备信息,便于定位物理拓扑。
portID: Ethernet0 # 邻居设备的端口标识符,如果对端为主机则为 mac 地址,如果是交换机则为 peer port 名称。
portName: Ethernet0 # 邻居设备端口名称,为网卡名称或端口名称。
sysName: SPINE01 #邻居设备的系统名称。
status: up
- name: Ethernet8
neighbor:
portID: Ethernet8
portName: Ethernet8
sysName: SPINE01
status: up
故障排查¶
如果在使用 Switch Port Detail 功能时遇到问题,可以按照以下步骤进行排查:
-
检查 Kubernetes 中的 SwitchEndpoint 资源是否存在,并且状态为 Connected:
-
检查 Kubernetes 中的 Unifabric Pod 是否正常运行:
-
登录交换机执行
show lldp summary命令,检查端口状态是否正常,邻居是否正常。 - 登录交换机执行
show logging命令,检查交换机日志是否有异常信息。
第三部分:存储节点接入¶
功能概述¶
Unifabric 支持将外部裸金属存储节点接入到 Kubernetes 集群中进行统一管理和监控。通过部署 unifabric agent 到存储节点上,agent 会采集存储节点的 RDMA 网络状态、LLDP 邻居信息等,并将数据上报到 k8s 集群中的 unifabric 控制平面。也可以在集群的 grafana 面板中查看存储节点的监控数据。
支持的存储服务器型号¶
通用的Linux服务器都支持接入。
基本要求¶
- 存储节点需要安装 Docker(要求支持 docker compose)
- 存储节点需要能够访问 Kubernetes 集群的 API Server
- 存储节点是具备 RDMA 网卡的裸金属服务器
- 待接入的 Kubernetes 集群中已经部署并运行 unifabric 组件
创建 kubeconfig 文件¶
在需要接入存储节点的 k8s 集群的控制节点上,执行以下命令生成 kubeconfig 文件:
# 指定 unifabric 安装的命名空间
UNIFABRIC_NAMESPACE="unifabric"
cat > cluster1-kubeconfig.yaml <<EOF
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: $(kubectl config view --raw -o jsonpath="{.clusters[0].cluster.certificate-authority-data}")
server: $(kubectl config view --raw -o jsonpath="{.clusters[0].cluster.server}")
name: $(kubectl config view --raw -o jsonpath="{.clusters[0].name}")
contexts:
- context:
cluster: $(kubectl config view --raw -o jsonpath="{.clusters[0].name}")
user: unifabric-sa-token
namespace: ${UNIFABRIC_NAMESPACE}
name: unifabric-sa-token@$(kubectl config view --raw -o jsonpath="{.clusters[0].name}")
current-context: unifabric-sa-token@$(kubectl config view --raw -o jsonpath="{.clusters[0].name}")
users:
- name: unifabric-sa-token
user:
token: $(kubectl get secret unifabric-sa-token -n ${UNIFABRIC_NAMESPACE} -o jsonpath='{.data.token}' | base64 -d)
EOF
该 kubeconfig 文件基于 unifabric 安装命名空间下的 ServiceAccount unifabric-sa-token 生成,仅包含访问 unifabric 所需要的最小权限。
在本地临时验证,确保 kubeconfig 文件内容正确:
kubectl --kubeconfig=cluster1-kubeconfig.yaml version
kubectl --kubeconfig=cluster1-kubeconfig.yaml get pods -A
将 kubeconfig 文件复制到存储节点服务器的 /etc/unifabric/cluster1-kubeconfig.yaml 路径下,方便下面步骤使用。
部署 lldp 和 unifabric agent(使用 Docker Compose)¶
本节介绍如何使用 Docker Compose 在存储节点上部署 lldp 和 unifabric agent 服务。在每个逻辑金属存储节点上执行以下步骤。
1. 运行 lldp 服务¶
在每一个存储主机上执行部署 unifabric-lldp 服务,每个主机即使接入多个 k8s 集群,也只需部署一个实例即可。首先创建 /etc/unifabric/lldp.yaml 文件:
sudo mkdir -p /etc/unifabric
cat <<'EOF' | sudo tee /etc/unifabric/lldp.yaml > /dev/null
services:
unifabric-lldp:
image: ${UNIFABRIC_AGENT_IMAGE}
container_name: unifabric-lldp
command: ["/usr/bin/unifabric/entrypoint.sh"]
network_mode: host
restart: always
privileged: true
environment:
# 节点 IP 信息(选填)
NODE_IPADDRESS: ${NODE_IPADDRESS}
# LLDP 发送间隔,单位秒(选填)
LLDPD_TX_INTERVAL: 30
# 要启用 LLDP 的接口,逗号分隔的列表
# LLDPD_INTERFACE_PATTERN: ""
volumes:
- /var/run:/var/run
- /etc/hostname:/etc/hostname:ro
healthcheck:
test: CMD-SHELL lldpcli -v || exit 1
interval: 5s
timeout: 3s
retries: 5
EOF
通过下面命令启动 lldp 服务。设置 UNIFABRIC_AGENT_IMAGE 环境变量指定 Agent 镜像版本,使用和 k8s 集群匹配的版本。可选设置 NODE_IPADDRESS 环境变量指定节点 IP 地址,该 IP 地址将用于 LLDP 广播。
UNIFABRIC_AGENT_IMAGE="release.daocloud.io/unifabric/unifabric-agent:latest" \
sudo -E docker compose -f /etc/unifabric/lldp.yaml up -d
2. 启动 unifabric-agent 服务¶
确保上节创建的 kubeconfig 在 /etc/unifabric/cluster1-kubeconfig.yaml 路径存在。
创建 unifabric agent 配置文件 /etc/unifabric/cluster1-agent-config.yaml:
export METRICS_PORT=5025
export STORAGE_RDMA_NIC_FILTER="interface=*"
cat <<EOF | sudo tee /etc/unifabric/cluster1-agent-config.yaml > /dev/null
inStorageNode: true
metrics:
port: ${METRICS_PORT}
rdmaNeighbor:
# 匹配存储 RDMA 网卡,支持通配符
storageRdmaNicFilter: "${STORAGE_RDMA_NIC_FILTER}"
EOF
inStorageNode是指示 Agent 运行在外部存储节点的方式,必须设置为true。metrics.port参数指定存储节点上用于暴露 metrics 的端口,默认是5025,可以根据需要修改,如果接入不同集群,修改使用不同端口以避免冲突。storageRdmaNicFilter参数用于匹配存储节点的 RDMA 网卡接口名称,支持通配符,例如ens*可以匹配所有以ens开头的接口名称。根据实际存储节点的网卡命名规则进行调整。
创建 Docker Compose 文件 /etc/unifabric/cluster1-agent-compose.yaml:
cat <<'EOF' | sudo tee /etc/unifabric/cluster1-agent-compose.yaml > /dev/null
services:
unifabric-agent:
image: ${UNIFABRIC_AGENT_IMAGE}
container_name: unifabric-agent
network_mode: host
restart: always
privileged: true
volumes:
- /etc/unifabric/cluster1-kubeconfig.yaml:/root/.kube/config
- /etc/unifabric/cluster1-agent-config.yaml:/etc/config/config.yaml
- /var/run:/var/run
- /etc/hostname:/etc/hostname:ro
- /proc:/host/proc:ro
command:
- /usr/bin/unifabric/agent
- -config
- /etc/config/config.yaml
EOF
UNIFABRIC_AGENT_IMAGE="release.daocloud.io/unifabric/unifabric-agent:latest" \
sudo -E docker compose -f /etc/unifabric/cluster1-agent-compose.yaml up -d
- 注意替换
UNIFABRIC_AGENT_TAG为 k8s 集群匹配的 image 版本,不同的集群可能需要使用不同版本的 Agent 镜像。 - 如果需要接入多个集群,可以复制该文件并修改服务名称和配置文件路径,例如
cluster1-agent-compose.yaml,并使用对应的 kubeconfig 和配置文件。
集群内配置存储节点 metrics 抓取¶
在要 k8s 集群控制节点,生成存储节点 metrics 抓取配置文件 unifabric-metrics-external.yaml:
# 设置存储节点 IP 列表,逗号分隔
export STORAGE_NODE_IPS="1.1.1.1,2.2.2.2"
# 设置存储节点 RDMA Agent metrics 端口
export AGENT_PORT_METRICS="5025"
# 设置存储节点 RDMA 延迟 metrics 端口
export RDMA_LATENCY_PORT_METRICS="5027"
# 生成配置文件内容
cat > unifabric-metrics-external.yaml << EOF
apiVersion: v1
kind: Service
metadata:
name: unifabric-metrics-external
namespace: unifabric
labels:
app: unifabric-metrics-external
spec:
clusterIP: None
ports:
- name: metrics-agent
port: ${AGENT_PORT_METRICS}
targetPort: ${AGENT_PORT_METRICS}
- name: metrics-rdma-latency-cluster1
port: ${RDMA_LATENCY_PORT_METRICS}
targetPort: ${RDMA_LATENCY_PORT_METRICS}
---
apiVersion: v1
kind: Endpoints
metadata:
name: unifabric-metrics-external
namespace: unifabric
subsets:
- addresses:
$(IFS=',' read -ra IPS <<< "$STORAGE_NODE_IPS"; for ip in "${IPS[@]}"; do echo " - ip: $ip"; done)
ports:
- name: metrics-agent
port: ${AGENT_PORT_METRICS}
- name: metrics-rdma-latency
port: ${RDMA_LATENCY_PORT_METRICS}
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: unifabric-metrics-external
namespace: unifabric
labels:
operator.insight.io/managed-by: insight
release: kube-prometheus-stack
spec:
selector:
matchLabels:
app: unifabric-metrics-external
namespaceSelector:
matchNames:
- unifabric
endpoints:
- port: metrics-agent
interval: 30s
path: /metrics
- port: metrics-rdma-latency
interval: 30s
path: /metrics
EOF
部署配置文件:
验证存储节点接入状态¶
通过下面命令可以看到新接入的节点:
然后查看存储节点 fabricnode YAML 信息,确认 RDMA 网卡和 LLDP 邻居信息已经采集:
示例输出:
apiVersion: unifabric.io/v1beta1
kind: FabricNode
metadata:
name: l-oss-2
status:
rdmaHealthy: true
scaleUp:
scaleUpHealthy: false
storageNics:
- ipv4: 172.16.1.41/24
ipv6: ""
lldpNeighbor:
description:
"SONiC Software Version: SONiC.CuOS_4.0-0.R_X86_64_ztp - HwSku:
ds730-32d - Distribution: 10.13 - Kernel: 4.19.0-12-2-amd64"
hostname: StorageSW
mac: 70:06:92:6e:32:64
mgmtIP: 10.193.77.211
port: Ethernet200
name: ens2np0
rdma: true
state: up
- ipv4: ""
ipv6: ""
lldpNeighbor:
description:
"SONiC Software Version: SONiC.CuOS_4.0-0.R_X86_64_ztp - HwSku:
ds730-32d - Distribution: 10.13 - Kernel: 4.19.0-12-2-amd64"
hostname: StorageSW
mac: 70:06:92:6e:32:64
mgmtIP: 10.193.77.211
port: Ethernet192
name: ens1np0
rdma: true
state: up
在交换机查看 lldp 邻居信息,确认存储节点已经通过 LLDP 广播:
查看存储节点的 metrics 数据:
在 kube-prometheus-stack 的 Grafana 中查看存储节点相关的监控面板,确保可以查看到存储节点的指标数据。
接入多个集群¶
如果需要将存储节点接入多个 Kubernetes 集群,可以为每个集群创建单独的 kubeconfig 和 agent 配置文件,然后创建对应的 Docker Compose 文件启动多个 unifabric agent 实例。例如,可以创建 cluster2-kubeconfig.yaml、cluster2-agent-config.yaml 和 cluster2-agent-compose.yaml,并使用不同的 metrics 端口以避免冲突。
卸载存储节点 Agent¶
通过下面命令可以卸载存储节点上的 unifabric 服务:
# 卸载 unifabric agent 服务
# 如果接入了多个集群,需要分别卸载对应的 agent 服务,例如 cluster2-agent-compose.yaml
docker compose down -f /etc/unifabric/cluster1-agent-compose.yaml
# 如果需要卸载 lldp 服务,可以执行:
docker compose down -f /etc/unifabric/lldp.yaml
# 如果需要删除所有配置文件,可以执行:
sudo rm -rf /etc/unifabric
故障排查¶
如果存储节点没有正常接入,可以通过查看 Agent 日志进行排查:
docker compose logs -f /etc/unifabric/cluster1-agent-compose.yaml
docker compose logs -f /etc/unifabric/lldp.yaml
如果日志中提示无法连接 Kubernetes 集群,请检查 /etc/unifabric/cluster1-kubeconfig.yaml 文件内容是否正确。可以使用 kubectl 命令测试连接:
如果没有 metrics 数据,可以检查存储节点的防火墙设置,确保 5025 端口开放。并 curl 测试 metrics 抓取:
第四部分:RDMA 拓扑识别配置¶
功能概述¶
Unifabric 的 RDMA 网络邻居发现功能是一个专为 RDMA 网络设计的综合性网络拓扑发现系统。该功能基于 LLDP 协议进行底层邻居发现,并在此基础上提供多种上层网络管理能力。核心功能包括:
- LLDP 邻居发现:基于 LLDP 协议的底层网络拓扑发现,支持所有类型的交换机设备
- RDMA 网络专用:目前专门针对基于 RoCE 协议的 RDMA 网络环境
- 网卡分类管理:区分 GPU 算力网络(computeNics)和存储网络(storageNics)
- rdmaNeighbor 分组:专门针对 GPU 算力网络的自动分组功能,用于 Scale-out 场景的节点拓扑管理
- Kubernetes 原生:深度集成到 Kubernetes 环境,通过 FabricNode CRD 管理网络状态
其中,rdmaNeighbor 是基于 LLDP 邻居发现的上层功能,专门用于 GPU 算力网络的拓扑分组,与存储网络无关。它通过分析节点间的 GPU 算力网络连接关系,自动将具有相同网络拓扑的节点分组,为 Scale-out 计算场景提供智能的节点管理能力。
GPU 网络分类概念¶
- GPU 算力网络(computeNics):用于 GPU 间通信、模型训练、推理计算的高速 RDMA 网络
- GPU 存储网络(storageNics):用于 GPU 与存储系统间数据传输的专用 RDMA 网络
架构设计¶
邻居发现功能采用分层架构设计:
__________________________________________________________________________________
| |
| RDMA 网络邻居发现 |
|__________________________________________________________________________________|
| LLDP邻居发现 | 交换机邻居上报 | 外部存储邻居上报 |
| (Host Neighbor) | (Switch Neighbor) | (Storage Neighbor) |
| | | |
| • GPU 算力网络 | • 交换机拓扑 | • 存储集群发现 |
| • GPU 存储网络 | • gnmi 集成 | • 跨集群连接 |
| • LLDP 协议 | • LLDP 协议 | • 存储路径优化 |
|________________________|________________________|________________________________|
LLDP 邻居发现¶
LLDP 邻居发现功能: Unifabric 运行 lldpd 守护进程通过 LLDP 协议自动发现 GPU 算力网络和 GPU 存储网络中的邻居设备,并同步到 FabricNode CRD 的 Status 字段中,以供 RDMA 网络中拓扑展示使用。
启用 RDMA 网络邻居发现功能¶
注意:该功能必须确保交换机开启 LLDP 协议,否则无法发现邻居设备。
最佳实践配置已经默认配置,参考 安装 Unifabric 以下是涉及该功能的 Helm values 详细参数说明:
features:
rdmaNeighbor:
# 开启扩展邻居发现功能
enabled: true
# FabricNode 同步 LLDP 邻居同步时间
timeToWaitSyncLLDPToFabricNode: 1m
# GPU 算力网络网卡筛选规则
# 用于筛选节点哪些 RDMA 网卡属于 computeNics
# 支持接口名称通配(interface=)或子网(cidr=)
# 示例:gpuRdmaNicFilter: "cidr=172.16.0.0/16"
gpuRdmaNicFilter: "interface=ens16*"
# GPU 存储网络网卡筛选规则
# 用于筛选节点哪些 RDMA 网卡属于 storageNics
storageRdmaNicFilter: "interface=ens17*"
# 示例:storageRdmaNicFilter: "cidr=172.17.0.0/16"
# LLDP 守护进程配置
lldpd:
# LLDP 报文发送间隔(秒)
txInterval: 30
# 管理 IP 配置模式, 默认为空,使用 Kubelet NodeIP 作为管理 IP
# 支持:IP地址列表 | 接口名称 | 自动选择(留空)
managementIPPattern: ""
# LLDP 启用接口配置, 如果为空表示作用与所有 RDMA 网卡
# 支持:具体接口 | 模式匹配 | 全部接口(留空)
interfaces: "ens*"
gpuRdmaNicFilter 和 storageRdmaNicFilter 配置说明¶
这些配置影响主机哪些 RDMA 物理网卡计入 FabricNode.status 的 computeNics 和 storageNics 中:
- 网卡分类优先级:优先检查 storageRdmaNicFilter,未匹配的归入 FabricNode.status 中 computeNics
- 如果 gpuRdmaNicFilter 和 storageRdmaNicFilter 同时未配置,主机所有物理网卡计入 FabricNode.status 中 computeNics
- 如果 gpuRdmaNicFilter 和 storageRdmaNicFilter 都配置,按照通配值正常筛选,分别计入 FabricNode.status 中 computeNics 和 storageNics
推荐配置:优先设置 storageRdmaNicFilter,未匹配的 RDMA 网卡自动归入 FabricNode.status 中 computeNics。
agent.config.rdmaNeighbor.lldpd.interfaces 配置说明¶
-
具体接口:
-
模式匹配:
-
排除模式:
-
全部接口(默认):
-
使用 Helm 部署或更新 Unifabric
验证 RDMA 网络邻居发现功能是否正常¶
-
检查 unifabric 组件(特别是 lldpd 容器)是否正常运行,lldpd 日志作为独立的 container 运行在 unifabric-agent pod 中:
-
检查 FabricNode CRD 中的 computeNics 和 storageNics 所有网卡的 lldpNeighbor 字段是否包含邻居信息:
注意: 由于 LLDP 邻居采集需要一定时间,默认情况下 unifabric-agent 会等待一分钟后才会将 LLDP 邻居信息同步到 FabricNode CRD 的 Status 字段中。如果需要调整等待时间,可以修改 Helm 参数
agent.config.rdmaNeighbor.timeToWaitSyncLLDPToFabricNode配置,默认为 1 分钟
apiVersion: unifabric.io/v1beta1
kind: FabricNode
metadata:
creationTimestamp: "2025-06-19T07:02:08Z"
generation: 1
name: sh-cube-master-3
resourceVersion: "48723802"
uid: aa85f55f-d87f-4fbe-8dbc-e3c9cc089943
spec: {}
status:
gpuNics:
- ipv4: 172.17.3.143/24
ipv6: ""
lldpNeighbor:
description: 'SONiC Software Version: SONiC.CuOS_4.0-0.R_X86_64_ztp - HwSku:
ds730-32d - Distribution: 10.13 - Kernel: 4.19.0-12-2-amd64'
hostname: LEAF03
mac: 70:06:92:6e:32:1c
mgmtIP: 10.193.77.203
port: Ethernet208
name: ens841np0
rdma: true
state: up
- ipv4: 172.17.4.143/24
ipv6: ""
lldpNeighbor:
description: 'SONiC Software Version: SONiC.CuOS_4.0-0.R_X86_64_ztp - HwSku:
ds730-32d - Distribution: 10.13 - Kernel: 4.19.0-12-2-amd64'
hostname: LEAF04
mac: 70:06:92:6e:34:5c
mgmtIP: 10.193.77.204
port: Ethernet208
name: ens842np0
rdma: true
state: up
- ipv4: 172.17.2.143/24
ipv6: ""
lldpNeighbor:
description: 'SONiC Software Version: SONiC.CuOS_4.0-0.R_X86_64_ztp - HwSku:
ds730-32d - Distribution: 10.13 - Kernel: 4.19.0-12-2-amd64'
hostname: LEAF02
mac: 70:06:92:6e:34:80
mgmtIP: 10.193.77.202
port: Ethernet200
name: ens835np0
rdma: true
state: up
- ipv4: 172.17.1.143/24
ipv6: ""
lldpNeighbor:
description: 'SONiC Software Version: SONiC.CuOS_4.0-0.R_X86_64_ztp - HwSku:
ds730-32d - Distribution: 10.13 - Kernel: 4.19.0-12-2-amd64'
hostname: LEAF01
mac: 70:06:92:6e:33:18
mgmtIP: 10.193.77.201
port: Ethernet208
name: ens834np0
rdma: true
state: up
rdmaHealthy: true
totalNics: 5
storageNics:
- ipv4: 172.16.1.143/24
ipv6: ""
lldpNeighbor:
description: 'SONiC Software Version: SONiC.CuOS_4.0-0.R_X86_64_ztp - HwSku:
ds730-32d - Distribution: 10.13 - Kernel: 4.19.0-12-2-amd64'
hostname: StorageSW
mac: 70:06:92:6e:32:64
mgmtIP: 10.193.77.211
port: Ethernet144
name: ens1np0
rdma: true
state: up
需要检查:
- gpuNics 中是否包括主机每一个 GPU 算力网卡,并且其 IP 地址、状态等是否符合预期,并且 lldpNeighbor 是否准确包含邻居设备的详细信息。
- storageNics 中是否包括主机每一个存储网卡,并且其 IP 地址、状态等是否符合预期,并且 lldpNeighbor 是否也准确包含邻居设备的详细信息。
- rdmaHealthy 表示如果所有 RDMA 网卡都 Ready(包括网卡状态,LLDP 邻居发现都正常) ,该字段为 true,否则为 false
- totalNics 表示主机所有 RDMA 网卡的总数,包括 gpuNics 和 storageNics
ScaleoutLeafGroup 自动分组功能¶
ScaleoutLeafGroup 负责基于上述 LLDP 邻居发现信息自动将具有相同 GPU 算力网络拓扑的节点分组管理, 并将分组信息同步到 ScaleoutLeafGroup CRD 的 Status 字段中,并且为属于同一个 ScaleoutLeafGroup 的节点打上一组相同的标签(默认 label key: dce.unifabric.io/scaleout-group, 可通过 Helm 参数 features.rdmaNeighbor.nodeTopoZoneLabelKey 自定义, value 为 group name)。 该功能为横向扩展(Scale-out)场景提供了智能的节点分组和网络拓扑管理能力。
工作原理¶
ScaleoutLeafGroup 自动分组功能依赖于 FabricNode CRD 的 Status 字段中的 LLDP 邻居发现信息,因此必须确保 FabricNode CRD 的 Status.computeNics 字段中的 LLDP 邻居发现正常上报并信息正确。默认情况下,unifabric-agent 等待一分钟后才会将 LLDP 邻居信息同步到 FabricNode CRD 的 Status 字段中。如果需要调整等待时间,可以修改 Helm 参数 features.rdmaNeighbor.timeToWaitSyncLLDPToFabricNode 配置,默认为 1 分钟。
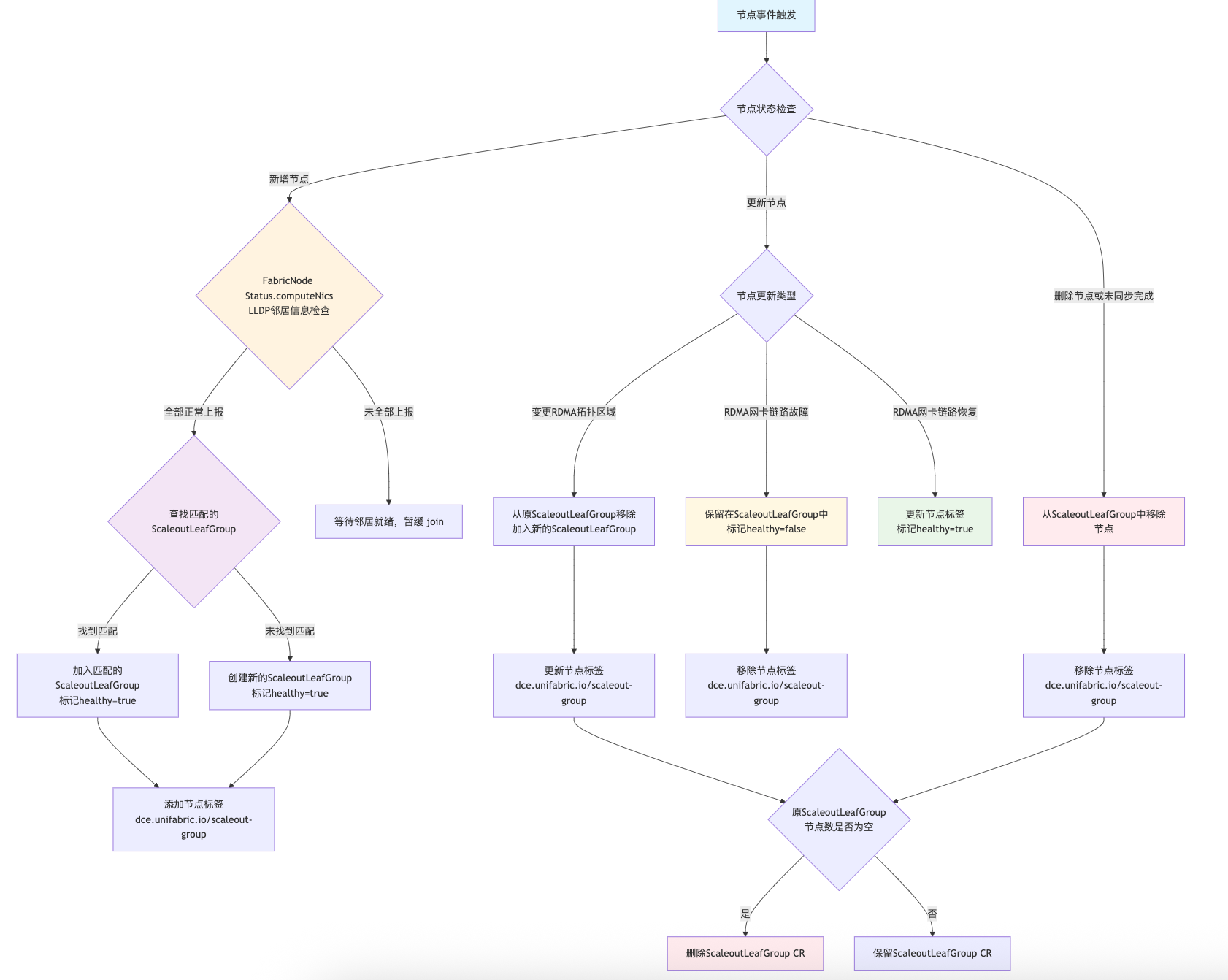
配置示例¶
在 Install.md 中已经默认开启此配置,如果您意外关闭,或者出现任何问题。可以参考一下内容重新配置:
在 Controller 组件中启用 ScaleoutLeafGroup 自动分组功能:
features:
rdmaNeighbor:
# 启用 RDMA 邻居发现功能
enabled: true
# 开启 ScaleoutLeafGroup 自动分组功能
enableScaleOutLeafGroup: true
# ScaleoutLeafGroup 自动分组标签 key
nodeTopoZoneLabelKey: dce.unifabric.io/scaleoutleaf-group
注意: 必须启用
features.rdmaNeighbor.enabled才能使features.rdmaNeighbor.enableScaleOutLeafGroup生效。
执行安装:
验证安装¶
-
检查 unifabric 组件是否正常运行:
-
检查 ScaleoutLeafGroup CRD 是否正常,一个 ScaleoutLeafGroup 对象代表一组具有相同 GPU 网络拓扑的节点。
~# kubectl get scaleoutleafgroups.unifabric.io NAME healthyNodes totalNodes healthy AGE 409bf491f7136a8a 4 4 true 6h1m上述信息中字段说明:
- NAME: 表示该 ScaleoutLeafGroup 的名称, 通过对该组内的所有交换机名称进行哈希算法得到
- healthyNodes: 表示该分组内健康的节点数量
- totalNodes: 表示该分组内节点的总数
- healthy :表示该分组是否健康,如果组内有一个节点不健康,则该分组不健康
- AGE: 表示该分组的创建时间
如下是一个 ScaleoutLeafGroup CRD 示例:
apiVersion: unifabric.io/v1beta1
kind: ScaleoutLeafGroup
metadata:
creationTimestamp: "2025-09-18T03:37:59Z"
generation: 1
name: 409bf491f7136a8a
resourceVersion: "85472900"
uid: e8d34e3a-d73f-4587-b39a-9f80a72631c0
spec: {}
status:
healthy: true # 表示该分组是否健康,如果组内有一个节点不健康,则该分组不健康
nodes: # 表示该分组包含的节点列表,其中每个节点都有 healthy 字段表示该节点的 RDMA 链路是否正常
- healthy: true
name: sh-cube-master-1
- healthy: true
name: sh-cube-master-2
- healthy: true
name: sh-cube-master-3
- healthy: true
name: sh-inf-worker-1
healthyNodes: # 表示该分组内健康的节点数量
totalNodes: # 表示该分组内节点的总数
switches: # 表示该分组包含所有节点连接的交换机列表
- LEAF01
- LEAF02
- LEAF03
- LEAF04
~# kubectl get nodes -l dce.unifabric.io/scaleoutleaf-group=409bf491f7136a8a
NAME STATUS ROLES AGE VERSION
sh-cube-master-1 Ready control-plane,fluent,gpu 130d v1.30.5
sh-cube-master-2 Ready control-plane,gpu 130d v1.30.5
sh-cube-master-3 Ready control-plane,gpu 130d v1.30.5
sh-inf-worker-1 Ready gpu 130d v1.30.5
如果节点从该分组中被移除,或者 RDMA 链路不正常时(healthy 为 false),unifabric 会移除该节点的 dce.unifabric.io/scaleoutleaf-group 标签。
存储主机邻居上报¶
注意: 此功能计划在后续版本中实现。
存储主机邻居上报功能将通过 RDMA 链路状态监控,实现对存储主机设备的拓扑发现和状态监控,为构建完整的网络拓扑视图提供关键的基础设施层信息。
交换机邻居上报¶
注意: 此功能计划在后续版本中实现。
交换机邻居上报功能将通过 gnmi 协议和交换机管理接口,实现对 RDMA 交换机设备的拓扑发现和状态监控,为构建完整的网络拓扑视图提供关键的基础设施层信息。
故障排查¶
参考故障排查