拓扑感知调度:为 AI 工作负载打造更智能的调度方案¶
原作者为 AI Infrastructure Learning Path 发表于 2025 年 11 月 25 日,相关标签为
#kubernetes #scheduling #topology #dra #device-plugin #gpu #nic
为什么是拓扑?为什么是现在?¶
在 KubeCon NA 2025 上,AI/ML 领域的讨论中有一个主题占据主导地位: 拓扑(Topology) 。每个人都在讨论拓扑感知调度,因为它对优化 AI 工作负载性能至关重要。

来源:Lightning Talk: Mind the Topology - Roman Baron, NVIDIA
现代 AI 工作负载,尤其是分布式训练和高性能推理,对硬件拓扑极其敏感。当 GPU、 网卡、CPU 和内存未能正确对齐在同一个 NUMA 节点、PCIe 根或网络结构中时,性能可能会下降 30-50% 甚至更多。
背景:当前拓扑调度支持现状¶
Device Plugin:传统方案¶
Kubernetes Device Plugin 一直是管理 GPU 等硬件资源的标准机制。Device Plugin API 提供了:
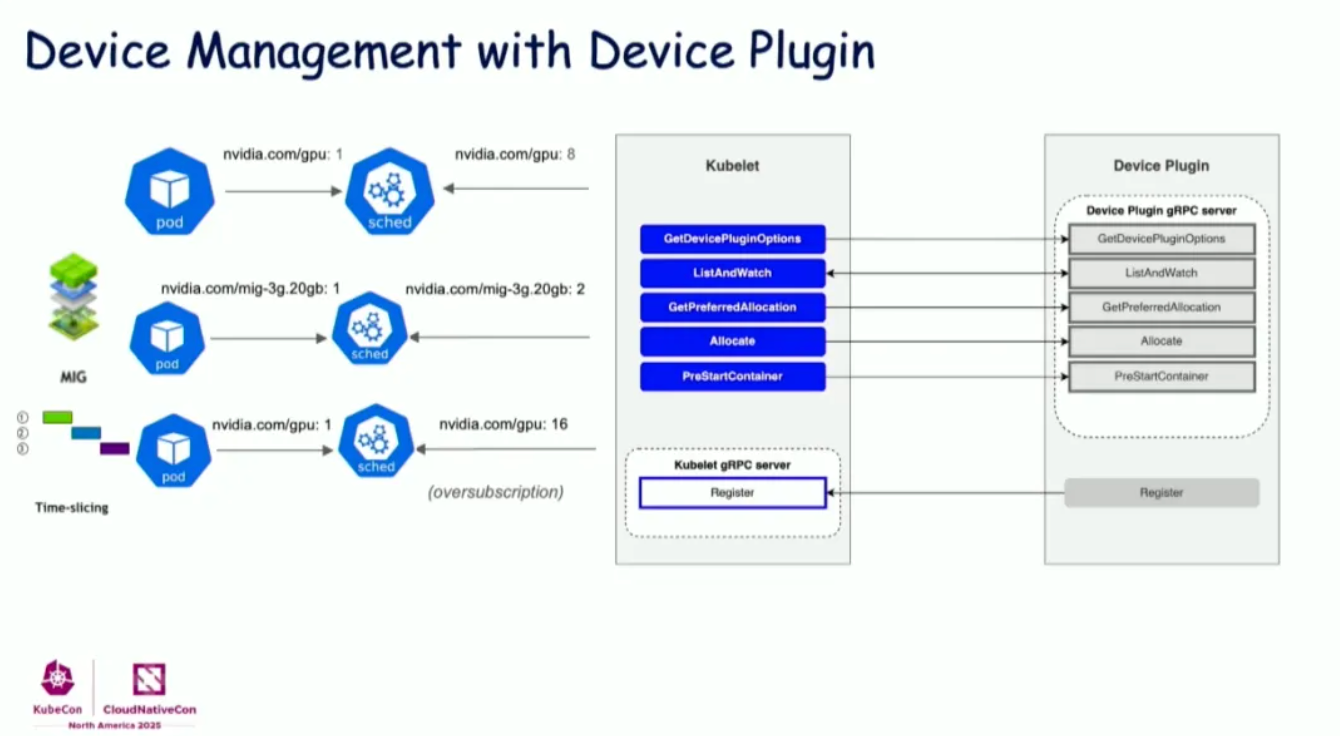
来源:KubeCon NA 2025: Device Management
核心组件:
- GetDevicePluginOptions: 插件配置
- ListAndWatch: 向 kubelet 报告可用设备
- GetPreferredAllocation: 建议最优设备分配(拓扑提示)
- Allocate: 为容器执行设备分配
- PreStartContainer: 容器启动前钩子
Device Plugin 支持:
- 基本 GPU 计数(例如
nvidia.com/gpu: 8) - MIG(多实例 GPU)分区
- 时间分片实现 GPU 超额订阅
Device Plugin 的局限性¶
然而,Device Plugin 在拓扑感知调度方面存在显著局限:
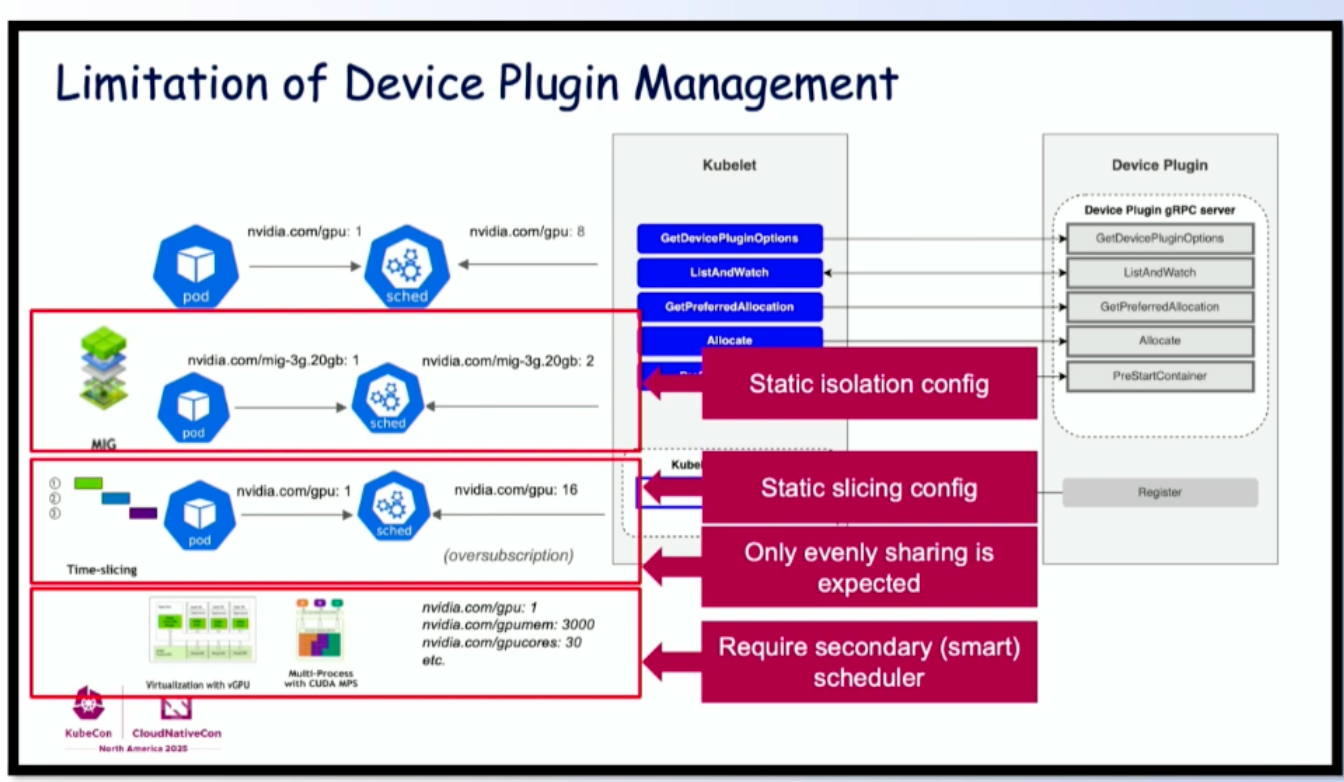
来源:KubeCon NA 2025: Device Management
- 静态隔离配置: MIG 配置必须预先定义
- 静态分片配置: 时间分片比例在部署时固定
- 仅支持均匀共享: 共享粒度有限
- 需要二级调度器: 复杂拓扑需要 Volcano 或 Kueue 等额外调度器
Kueue:拓扑感知调度¶
Kueue 通过节点标签提供拓扑感知调度。它使用分层拓扑级别:
# 机架/区块拓扑的节点标签
cloud.google.com/gce-topology-block: "block-1"
cloud.google.com/gce-topology-subblock: "subblock-1"
cloud.google.com/gce-topology-host: "host-1"
kubernetes.io/hostname: "node-1"
Kueue 支持:
- 拓扑感知调度: 将工作负载 Pod 放置在具有匹配拓扑的节点上
- 基于 Cohort 的资源共享: 在拓扑组内共享资源
- 带拓扑的 Gang 调度: 确保所有 gang 成员拓扑对齐
Kueue 拓扑配置示例:
apiVersion: kueue.x-k8s.io/v1beta1
kind: ResourceFlavor
metadata:
name: gpu-topology
spec:
nodeLabels:
cloud.google.com/gce-topology-block: "block-1"
nodeTaints:
- effect: NoSchedule
key: nvidia.com/gpu
value: "present"
Volcano:带拓扑的 Gang 调度¶
Volcano 提供高级调度功能,包括:
- Gang 调度: 分布式工作负载的全有或全无调度
- 拓扑插件: 在调度决策中考虑 GPU 拓扑
- 网络感知调度: RDMA/InfiniBand 网络结构感知
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
metadata:
name: distributed-training
spec:
minMember: 8
minResources:
nvidia.com/gpu: "8"
queue: training-queue
# NVLink 连接的拓扑亲和性
topologyPolicy: "best-effort"
DRA:下一代拓扑管理¶
动态资源分配(DRA) 代表了 Kubernetes 处理设备拓扑方式的根本性转变。DRA 提供结构化参数,实现丰富的拓扑表达和约束规范。
DRA 如何处理拓扑感知调度¶
DRA 使用 属性(attributes) 和 约束(constraints) 配合 CEL(通用表达式 语言)来表达拓扑需求。关键机制包括:
-
设备属性: 每个设备发布拓扑信息
pcieRoot:PCIe 层次结构标识符numaNode:NUMA 节点关联nvlinkDomain:NVLink 结构标识符rdmaDevice:关联的 RDMA 网卡
-
约束: 强制执行拓扑规则的 CEL 表达式
- GPU 和网卡在同一 PCIe 根
- CPU 和内存在同一 NUMA 节点
- GPU 之间的 NVLink 连接
-
SharedID: 同一拓扑域中的设备获得共享标识符
GPU + 网卡拓扑协调¶
DRA 拓扑最强大的用例是协调 GPU 和网卡在同一 PCIe 根上的分配。这对于使用 GPU-Direct 的基于 RDMA 的分布式训练至关重要。
带 PCIe 拓扑约束的 ResourceClaimTemplate 示例:
apiVersion: resource.k8s.io/v1beta1
kind: ResourceClaimTemplate
metadata:
name: gpu-nic-topology
spec:
spec:
devices:
requests:
- name: gpu
deviceClassName: nvidia-gpu
count: 1
- name: rdma-nic
deviceClassName: rdma-nic
count: 1
constraints:
# GPU 和网卡必须在同一 PCIe 根上
- requests: ["gpu", "rdma-nic"]
matchAttribute: pcieRoot
工作原理:
- DRA 调度器评估可用的 GPU 和网卡
- 对于每个候选 GPU,它找到同一 PCIe 根上的网卡
- 只考虑满足约束的分配
matchAttribute: pcieRoot确保两个设备共享相同的 PCIe 拓扑
DRANET:网络设备 DRA¶
DRANET 是 Google 的网络设备 DRA 实现。 它使用节点标签与 Kueue 的拓扑感知调度集成:
# DRANET 使用这些标签进行拓扑感知
cloud.google.com/gce-topology-block
cloud.google.com/gce-topology-subblock
cloud.google.com/gce-topology-host
kubernetes.io/hostname
DRANET + NVIDIA GPU DRA 可以协调:
- RDMA 网卡与 GPU 在同一 PCIe 结构上分配
- 分布式训练的多网卡配置
- 使用 SR-IOV VF 的网络隔离
CPU 微拓扑支持¶
dra-driver-cpu 项目正在添加 CPU 微拓扑支持,包括:
- NUMA 感知的 CPU 分配
- 带拓扑对齐的 CPU 绑定
- 与 GPU NUMA 放置的协调
DRAConsumableCapacity:Kubernetes 1.34 新特性¶
DRA 的一个重大进步是 DRAConsumableCapacity 功能:

来源:KubeCon NA 2025: Device Management
关键能力:
- Alpha 功能,在 Kubernetes 1.34 中引入
- 建议从 Kubernetes 1.35 开始使用(仍处于 Alpha 阶段)
核心能力:
- 允许多次分配: 跨多个资源请求
- 可消耗容量: 保证的资源共享
潜在用例:
- 虚拟 GPU 内存分区
- 虚拟网卡(vNIC)共享
- 带宽限制的网络分配
- I/O 带宽智能存储设备共享
- 原生资源请求(CPU)
这实现了更灵活的资源共享,同时保持拓扑感知。
挑战:从 Device Plugin 迁移到 DRA¶
许多组织在基于 Device Plugin 的解决方案上投入了大量资源。迁移到 DRA 面临几个挑战:
1. 现有 Device Plugin 投资¶
组织可能有:
- 带拓扑逻辑的自定义 Device Plugin
- 与监控和可观测性工具的集成
- 依赖 Device Plugin API 的 Operator 工作流
2. 共存问题¶
同时运行 Device Plugin 和 DRA 可能导致:
- 资源冲突: 同一设备由两个系统管理
- 拓扑不一致: 系统之间拓扑视图不同
- 调度混乱: 调度器没有统一视图
3. 功能差距¶
一些 Device Plugin 功能还没有 DRA 等效实现:
- 设备健康监控: Device Plugin 有内置健康检查
- 热插拔支持: Device Plugin 支持动态设备添加
- 指标集成: 来自 Device Plugin 的 Prometheus 指标
解决方案和变通方法¶
DRA 扩展能力:
- DRA 驱动可以实现兼容层
- NVIDIA 的 DRA 驱动支持 Device Plugin 迁移路径
- NRI 集成可以弥补运行时级别的差距
推荐迁移路径:
- 在现有 Device Plugin 旁边部署 DRA 驱动
- 使用节点污点分隔工作负载
- 逐步将工作负载迁移到基于 DRA 的资源声明
- 所有工作负载迁移后淘汰 Device Plugin
相关 KubeCon 演讲¶
KubeCon NA 2025 的几个精彩演讲涵盖了这些主题:
Lightning Talk: Mind the Topology¶
Mind the Topology: Smarter Scheduling for AI Workloads on Kubernetes - Roman Baron, NVIDIA
主要内容:
- 为什么拓扑对 AI 工作负载很重要
- NVIDIA KAI Scheduler 实现拓扑感知调度
- NVIDIA KAI-Scheduler
Device Management 深度解析¶
主要内容:
- 从 Device Plugin 到 DRA 的演进
- DRAConsumableCapacity 功能
- 多设备拓扑协调
拓扑感知调度最佳实践¶
-
理解你的拓扑需求
- 分析工作负载以识别拓扑敏感性
- 映射硬件拓扑(PCIe、NUMA、NVLink、RDMA)
-
选择正确的调度方式
- 简单 GPU 工作负载:Device Plugin + Topology Manager
- 复杂多设备:带约束的 DRA
- 分布式训练:Kueue 或 Volcano + DRA
-
为节点添加拓扑信息标签
- 使用一致的标签方案
- 包含机架、区块和主机级拓扑
-
测试拓扑影响
- 使用和不使用拓扑对齐进行基准测试
- 测量延迟和吞吐量差异
-
规划迁移
- 从新工作负载开始使用 DRA
- 创建兼容性测试
- 记录拓扑需求
结论¶
拓扑感知调度已从一个锦上添花的功能发展为 AI 工作负载的关键需求。从 Device Plugin 到 DRA 的过渡代表了 Kubernetes 管理硬件拓扑方式的根本性转变:
- Device Plugin: 简单、成熟,但拓扑支持有限
- DRA: 丰富的拓扑表达、多设备协调,是 Kubernetes 设备管理的未来
随着 AI 工作负载复杂性的持续增长,对精细拓扑感知调度的需求只会增加。无论你使用 Kueue、Volcano 还是原生 Kubernetes 调度,理解拓扑并规划 DRA 采用对于优化 AI 基础设施至关重要。