优化故障转移延迟灵敏度¶
多云支持应用的跨集群自动故障转移,从而保障应用在多个集群部署的稳定性。 影响故障转移的延时时效的主要有以下 2 个维度的指标,需要组合配置才能最终达到延迟灵敏度的效果。
- 集群维度:标记集群为不健康的检查时长、集群驱逐容忍时长
- 工作负载维度:集群污点容忍时长
Failover 特性介绍¶
在 DCE 5.0 多云编排中启用了 failover 之后,提供了以下一些参数配置选项:
| 参数 | 定义 | 描述 | 字段名EN | 字段名ZH | 默认值 |
|---|---|---|---|---|---|
| ClusterMonitorPeriod | 检查周期间隔 | 检查集群状态的时间间隔 | Check Internal | 检查时间间隔 | 60s |
| ClusterMonitorGracePeriod | 运行中标记集群不健康检查时长 | 集群运行中,超过此配置时间未获取集群健康状态信息,将集群标记为不健康 | The runtime marks the duration of an unhealthy check | 运行时标记不健康检查时长 | 40s |
| ClusterStartupGracePeriod | 启动时标记集群不健康的检查时长 | 集群启动时,超过此配置时间未获取集群健康状态信息,将集群标记为不健康 | Mark health check duration at startup | 启动时标记健康检查时长 | 600s |
| FailoverEvictionTimeout | 驱逐容忍时长 | 集群被标记为不健康后,超过此时长会给集群打上污点,并进入驱逐状态 (集群会增加驱逐污点) | Eviction tolerance time | 驱逐容忍时长 | 30s |
| ClusterTaintEvictionRetryFrequency | 优雅驱逐超时时长 | 进入优雅驱逐队列后,最长等待时长,超时后会立即删除 | Graceful ejection timeout duration | 优雅驱逐超时时长 | 5s |
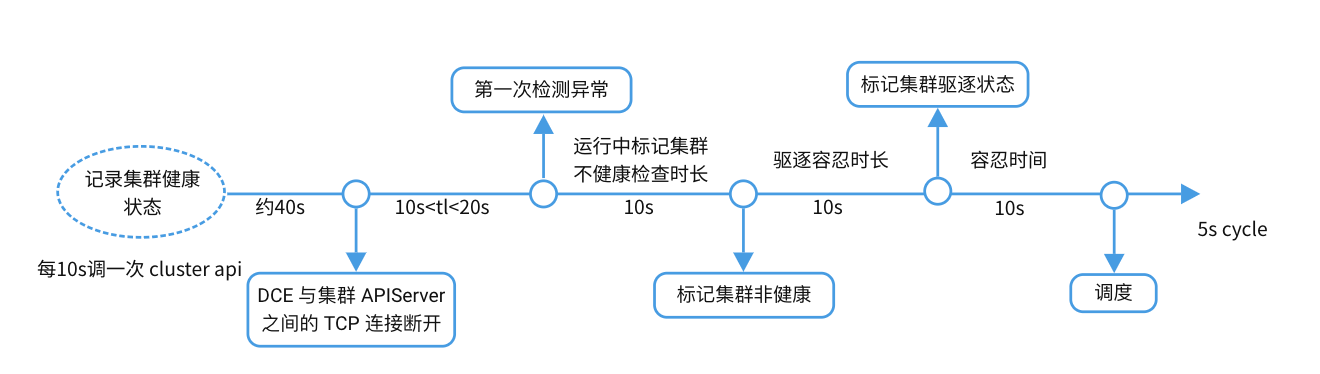
工作负载被驱逐的时间线¶
简单解释下图:我们规定 10s 调用一次集群的 API 用以记录集群的健康状态,当四次结果均为健康时,我们才认定集群是健康状态。 此时我们将 DCE 与集群 APIserver 之间的 TCP 断开 10s-20s 之内,若没有获取到集群的健康状态将认为集群异常, 指定时间内若集群没有恢复健康,将被标记为非健康状态,同时打上 NoSchedule 的污点,超过指定的驱逐容忍时长后, 将被打上 NoExecute 的污点,最终被驱逐。
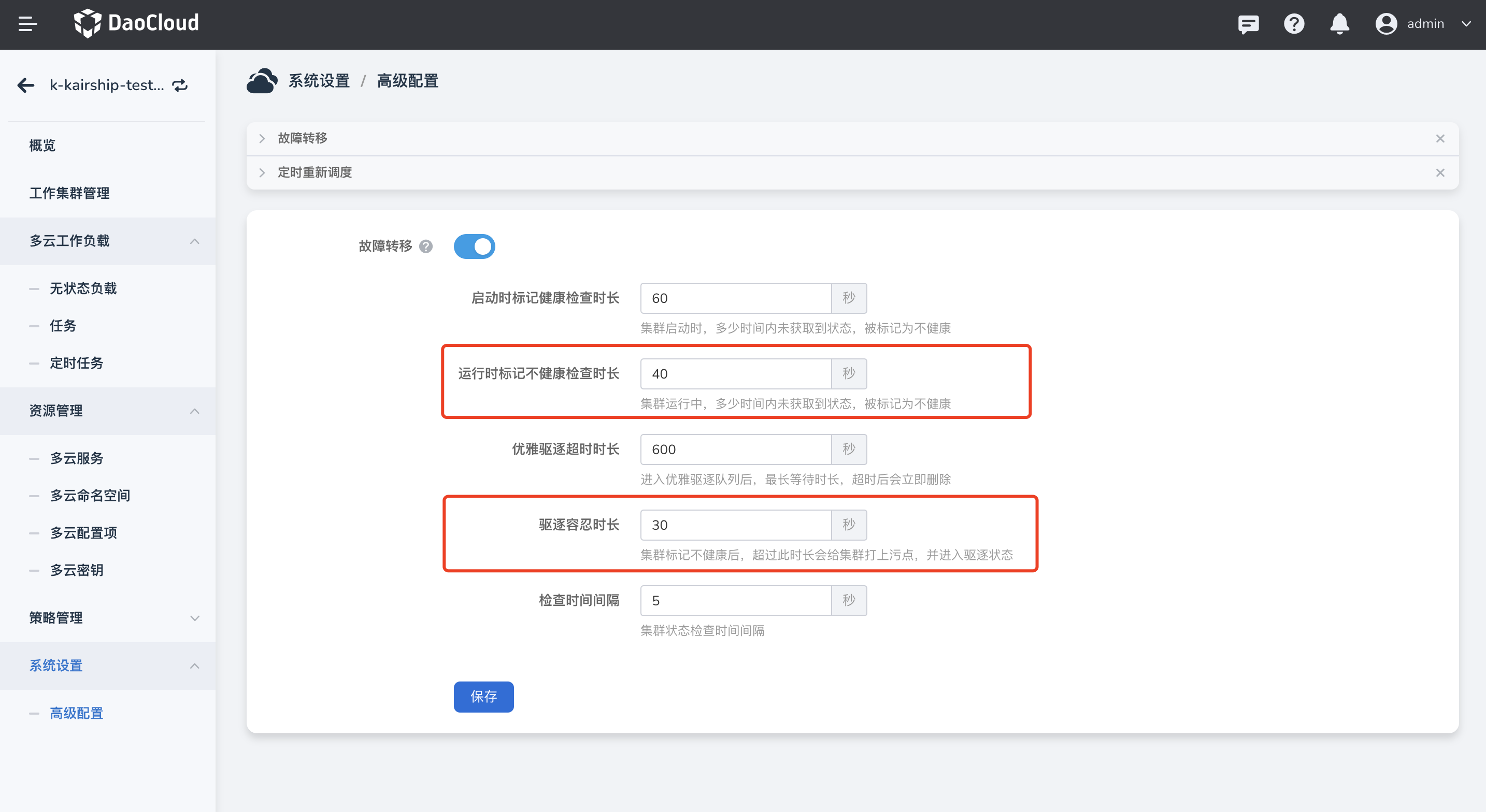
多云实例的优化配置¶
多云实例需要进入高级设置->故障转移部分,以下配置可参考上图填写参数信息。
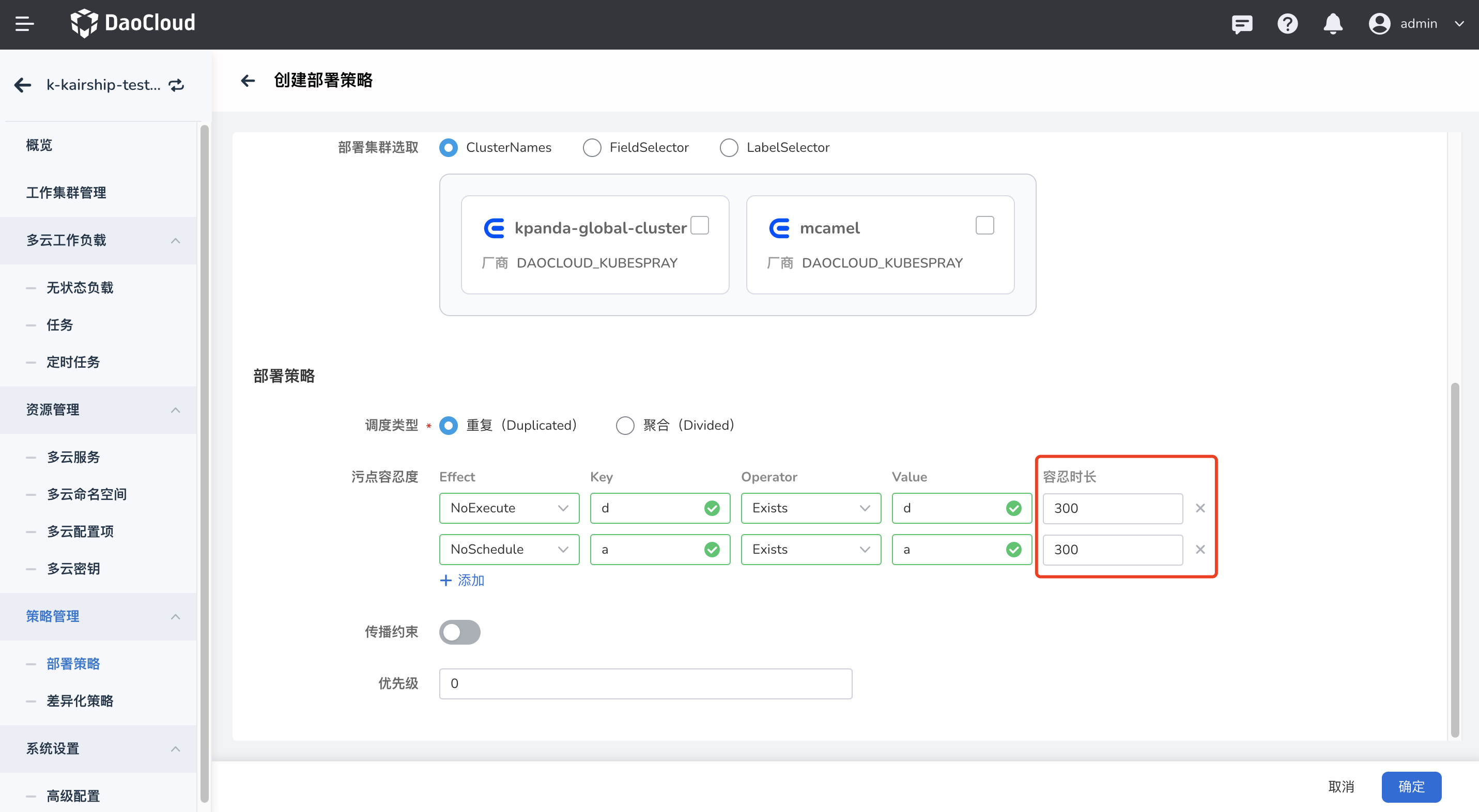
多云工作负载的配置优化¶
多云工作负载主要和其部署策略(PP)相关,需要在部署策略中修改对应的集群污点容忍时长。