vLLM Elastic EP:MoE 推理终于可以“在线扩缩容”了¶
素材源于 vllm.ai/blog
随着 DeepSeek、Qwen-MoE 等混合专家(MoE)模型的快速普及,以及 Agentic AI、强化学习(RL)场景的爆发式增长,如何稳定、高效地支撑超大规模 MoE 推理,已成为 AI 基础设施领域的核心痛点。中国信通院《大模型推理优化关键技术及应用实践研究报告(2026年)》指出,流量波动带来的弹性适配难题,正成为制约 MoE 模型规模化落地的关键瓶颈之一。
在 MoE 推理体系中,专家并行(EP)是提升吞吐的核心技术——尤其是在 WideEP 场景下,EP 可跨越大量 Worker,显著扩大 KV Cache 容量,完美支撑更高并发、更长上下文,以及复杂的 Agent 多轮对话需求,这也是当前 DeepSeek 等主流 MoE 模型部署的核心方案之一。
但长期以来,vLLM 与大多数推理框架一样,都面临一个致命短板:
EP 是“静态”的。
一旦推理服务启动,整个集群的并行拓扑、GPU 数量以及专家分布就被完全固定,无法根据业务流量动态调整。这对追求高可用、高性价比的生产环境而言,几乎是“不可接受”的。
具体来说,静态 EP 的痛点的体现在三个方面:
- 流量峰值时,无法在线扩容,GPU 直接打满,导致请求排队、时延飙升,甚至触发 SLA 违约;
- 流量低谷时,无法在线缩容,GPU 长时间闲置,造成算力资源浪费——要知道,超过60%的算力浪费源于硬件资源错配,这在 MoE 推理场景中尤为突出;
- 任何规模调整,都需要整体重启服务,而重启就意味着请求中断、服务抖动、连接重建,甚至影响业务连续性。
尤其是在 RL、Agent、多轮对话等场景中,推理任务普遍具备超长上下文、持续会话、高吞吐、GPU 长时间占用的特点,传统静态 EP 早已难以适配真实生产需求。
而 vLLM 最新引入的 Elastic EP(弹性专家并行) ,正是为解决这一痛点而来——它让 MoE 推理首次具备“运行时动态扩缩容”能力,也为云原生 AI 基础设施的演进提供了关键支撑,这与 DaoCloud 深耕云原生、赋能 AI 规模化落地的核心理念高度契合。
什么是 Elastic EP?核心就是“无需重启,弹性应变”¶
Elastic EP 的核心目标非常直白,却极具行业突破性:
让 MoE 推理服务具备“运行时动态扩缩容”能力,无需重启服务,即可灵活调整算力规模。
它允许 vLLM 在服务正常运行过程中,动态增加或减少数据并行(DP)Worker 数量,整个过程对业务无感知。实现这一能力,仅需一个简单的 API 调用:
curl -X POST http://localhost:8000/scale_elastic_ep \
-H "Content-Type: application/json" \
-d '{"new_data_parallel_size": 8}'
一行命令,vLLM 就能自动完成以下操作,全程无需人工干预、无需重启服务:
- 动态调整 DP 规模,适配当前业务流量;
- 重建 EP 并行拓扑,保证推理效率;
- 重新分配专家节点,平衡算力负载;
- 接管新的 GPU 资源,快速提升推理容量;
- 无缝完成扩缩容,业务请求正常流转。
这意味着,MoE 推理终于摆脱了“静态绑定”的束缚:GPU 可按需动态调度,推理容量可实时匹配流量变化,服务无需“停机升级”,真正实现了 MoE 推理的云原生弹性——这也是 DaoCloud 所倡导的“算力弹性化、服务高可用”的核心体现。
Elastic EP 为什么重要?解决3大核心行业痛点¶
Elastic EP 绝非“简单的在线扩容”,而是从根源上解决了 MoE 推理体系中的3大核心难题,尤其适配企业级生产环境的实际需求,这也是其能成为下一代 AI Infra 核心能力的关键。
1. 提升 GPU 利用率,降低算力成本¶
传统静态 EP 的最大痛点的是“算力规划难”:预估不足会导致高峰期卡顿,预估过高则会造成 GPU 闲置。而在当前 DRAM/SSD 价格上涨、算力成本高企的背景下,这种资源浪费无疑会加重企业负担。
Elastic EP 则实现了 GPU 资源的“按需分配”:高峰期自动扩容,最大化利用算力支撑业务;低峰期自动缩容,回收闲置 GPU 资源分配给其他任务。这种弹性调度,能有效提升 GPU 利用率,真正实现“算力不浪费、成本可可控”,与 DaoCloud 算力资源池化、高效调度的能力形成互补。
2. 完美适配 Agent 与 RL 场景,支撑业务爆发¶
Agent 与强化学习推理,是当前 AI 落地的核心场景之一,这类场景有两个典型特点:一是长上下文,多轮对话会持续增长 KV Cache,对显存容量要求极高;二是高并发,大量 Agent 同时运行,需要海量算力支撑。
WideEP 技术通过扩展 EP 规模提升 KV Cache 容量,而 Elastic EP 则让这种能力“动态化”:当对话上下文变长、Agent 数量增多时,系统自动扩容 GPU,保障推理流畅;当会话减少、任务结束时,自动回收 GPU,避免资源闲置。
这一点至关重要——随着 Agentic AI 向工业、金融等领域渗透,对推理基础设施的灵活性要求持续提升,Elastic EP 正是支撑这类业务爆发的关键技术,与 DaoCloud “工业+智能”的布局高度契合。
3. 为容错能力打基础,保障服务高可用¶
对企业级服务而言,高可用是底线。而 Elastic EP 最具长远价值的意义,在于它构建了 vLLM 容错体系的核心基础设施——一旦某个 GPU 或 Rank 出现故障,需要重新分布专家、重建通信组、接管任务,这些本质上都是“运行时拓扑重配置”,而 Elastic EP 恰好提供了这一能力路径。
未来,vLLM 的故障恢复流程将实现全自动化,无需人工干预、无需重启服务:
- 系统自动检测 GPU/Rank 故障;
- 触发自动缩容,剔除故障节点;
- 迁移故障节点上的专家权重;
- 补充新的 GPU 资源;
- 自动扩容恢复,服务恢复正常。
也正因为如此,vLLM 官方明确将 Elastic EP 视为“容错专家并行”的核心组成部分——这与 DaoCloud 保障企业级服务高可用的核心诉求完全一致。
Elastic EP 到底难在哪?不止是“多启动几个 Worker”¶
很多人会觉得,在线扩缩容不过是“多启动几个 Worker”,但实际上,MoE 推理的在线扩缩容,远比传统 Web 服务复杂得多——因为 EP 规模的变化,会导致大量运行时状态失效,稍有不慎就会造成服务中断、请求失败。
这些失效的状态包括:
- 通信组变化,原有数据传输链路失效;
- 专家映射变化,推理任务路由规则需要重新调整;
- 权重归属变化,GPU 间的权重同步需要重新进行;
- CUDA Graph、torch.compile 状态失效,推理加速机制需要重启;
- Rank 拓扑变化,整个分布式推理的协同逻辑需要重构。
简单来说,Elastic EP 本质上是在“运行中的分布式推理系统”里,动态重构整个并行拓扑——而最难的点在于: 旧请求还在执行,新拓扑已经开始构建 ,如何避免两者冲突,是技术实现的核心难点。
为了解决这个问题,vLLM 设计了一个非常巧妙的方案—— Standby Group(备用通信组) ,其核心思路与 Kubernetes 的 Rolling Update(滚动更新)异曲同工,也是云原生技术在 AI 推理领域的典型应用:
新拓扑先在后台偷偷准备好,全部就绪后再统一切换,旧拓扑继续服务直到切换完成。
具体实现逻辑如下:
- 旧通信组继续处理当前请求,保障业务不中断;
- 新通信组在后台异步创建,新 Worker 提前完成初始化;
- 提前同步相关权重,做好切换准备;
- 等新拓扑、新通信组全部就绪后,一次性完成切换,销毁旧组。
这种设计,完美避免了服务停顿、全局阻塞、大规模请求失败的问题,既保证了弹性扩缩容的灵活性,又兼顾了企业级服务的稳定性——这与 DaoCloud 基于 Kubernetes 构建云原生基础设施的技术理念高度契合,也是 Elastic EP 能快速落地企业生产环境的关键。
Elastic EP 扩容流程:6 步实现“无缝弹性”¶
了解了核心设计,我们再来看 Elastic EP 的完整扩容流程——整个过程分为6个阶段,全程无需重启服务,对业务完全无感知,可直接适配企业级生产部署:
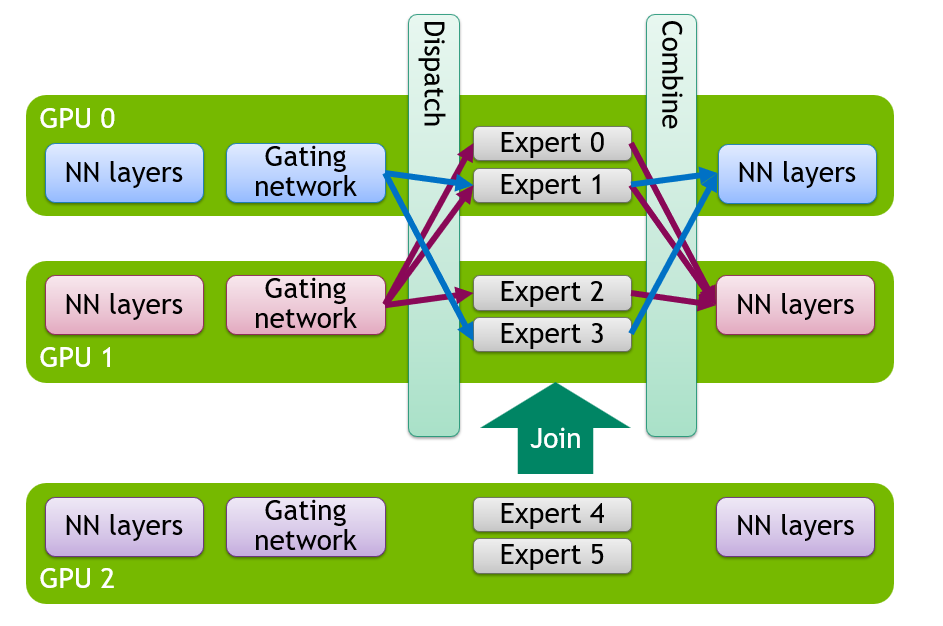
1. 接收扩容请求¶
通过调用以下 API 发起扩容请求,可指定新的 DP 规模:
如果开启 Drain 模式(设置环境变量 VLLM_ELASTIC_EP_DRAIN_REQUESTS=1),系统会先等待正在执行的请求全部完成,再进入扩容流程,进一步避免请求中断。
2. 启动新的 Worker¶
vLLM 当前依赖 Ray DP Backend 实现分布式部署,扩容时:
- Ray 自动拉起新的 GPU Worker,分配相应算力资源;
- 新 Rank 完成模型初始化,同步当前的专家映射信息;
- 新 Worker 进入待命状态,等待后续同步和切换。
注意:此时新 Worker 还未真正参与推理,避免影响当前正在执行的任务。
3. 创建备用通信组(核心步骤)¶
这是 Elastic EP 最关键的一步——vLLM 不会直接销毁旧通信组,而是在后台构建新的通信组(Standby Group):
- 旧拓扑、旧通信组继续处理请求,保障业务连续性;
- 新拓扑、新通信组在后台异步构建,完成通信链路初始化;
- 备用通信组提前完成测试,确保切换后能正常工作。
这样一来,即使在扩容过程中,推理任务的 Forward 操作也能正常执行,不会出现服务卡顿。
4. 权重同步¶
备用通信组就绪后,开始进行权重同步,确保新 Worker 与旧 Worker 的模型权重一致。同步的内容包括:
- Attention 权重、Embedding 权重、Norm 权重;
- 非专家权重(专家权重暂不迁移,等待拓扑切换后统一处理)。
为了提升同步效率,vLLM 会利用 NVLink、RDMA、GPU P2P 等高速传输技术,实现 GPU 间的低延迟、高带宽权重传输,这与华为昇腾推理部署中采用的灵衢互联与分层传输技术异曲同工,均为了降低调度与传输开销。
5. 拓扑切换(切换时刻)¶
当备用通信组、新 Worker、权重同步全部就绪后,进入真正的切换环节,vLLM 会依次执行以下操作:
- 释放旧的 CUDA Graph,重置 torch.compile 状态;
- 激活新的 EP/DP Group,启用备用通信组;
- 销毁旧的通信组,释放闲置资源;
- 重新进行 Warmup,确保新拓扑的推理性能。
至此,新拓扑正式生效,新 Worker 开始参与推理任务。
6. EPLB 重新分配专家¶
最后,EPLB(专家负载均衡)模块会重新分配专家节点,将旧 Worker 上的专家权重迁移到新 Worker 上,平衡各 GPU 的负载,确保推理效率最优。
整个扩容流程完成,全程无需重启服务,业务请求无中断、无抖动——这正是企业级 AI 推理服务所需要的核心能力。
缩容为什么更复杂?先迁移,再下线¶
很多人会觉得“缩容比扩容简单”,只需删除几个 Worker 即可,但事实恰恰相反——缩容的难度远高于扩容,核心原因在于: 被删除的 Rank 可能还持有专家权重 。
如果直接下线持有专家权重的 Worker,会导致推理任务因无法找到对应专家而失败。因此,缩容的核心逻辑是“先迁移,再下线”:
- 先将被删除 Rank 上的专家权重,迁移到其他正常运行的 Worker 上;
- 更新专家映射规则,确保推理任务能正确路由到新的专家节点;
- 回收被删除 Rank 的专家归属,确认无任务依赖后,再安全下线 GPU。
这一流程看似简单,却需要精准的负载均衡和权重迁移机制,避免出现专家迁移过程中的性能抖动,这也是 Elastic EP 技术实现的难点之一。
双阶段 Barrier:解决“半数 Worker 已切换”的死锁难题¶
Elastic EP 还有一个非常巧妙的工程设计—— 双阶段 Barrier ,专门解决分布式推理中“部分 Worker 已切换、部分未切换”的同步难题。
由于 DP Worker 是异步运行的,在拓扑切换过程中,很容易出现“有些 Rank 已进入新拓扑阶段,有些 Rank 还在执行旧拓扑的 Forward 操作”的情况——如果不进行同步,会导致通信组分裂、任务混跑,最终引发系统死锁。
双阶段 Barrier 的核心逻辑,就是实现所有 Worker 的“同步切换”:
第一阶段(带超时)¶
系统检查所有 Rank 的状态,如果发现还有 Rank 未完成旧任务、未准备好切换,已到达切换节点的 Rank 不会提前切换,而是继续执行一步 Forward 操作,等待未就绪的 Rank。
第二阶段(统一切换)¶
等所有 Rank 都到达同一切换边界、全部准备就绪后,系统再发出统一指令,所有 Rank 同时进入新拓扑阶段,完成切换。
这种设计既避免了系统死锁,又保证了切换过程的流畅性,是 Elastic EP 能稳定运行的关键细节,也体现了 vLLM 在工程实现上的严谨性。
NIXL EP:未来容错与弹性的核心支撑¶
除了核心的 Elastic EP 机制,vLLM 还引入了一个重要的通信后端—— NIXL EP ,它将成为未来 Elastic EP 容错能力和弹性性能的关键支撑,也是云原生 AI 推理的重要技术演进方向。
传统 EP Backend 在扩缩容时,需要重建全部通信连接,不仅初始化开销巨大,还会导致切换延迟增加,影响服务性能。而 NIXL EP 则实现了“增量连接管理”,支持两个核心接口:
- connect_ranks():增量添加新的通信连接;
- disconnect_ranks():增量删除无用的通信连接。
这种增量修改的方式,无需重建全部连接,带来的好处非常明显:
- 扩缩容速度更快,切换延迟大幅降低;
- 切换开销更小,避免对推理性能造成影响;
- 容错能力更强,故障节点切换时无需重建整个通信组;
- 故障恢复更简单,可快速补充新节点、恢复服务。
结合 SGLang 等框架中与 NIXL 无缝集成的实践经验,未来 NIXL EP 很可能成为 Elastic EP 的默认通信后端,进一步提升 MoE 推理的弹性和容错能力,为企业级大规模部署奠定基础。
Elastic EP 的意义:vLLM 迈向云原生推理基础设施¶
从表面上看,Elastic EP 只是给 vLLM 增加了一个在线扩缩容 API,但从更深层次来看,它标志着 vLLM 正在从“高性能推理框架”,真正走向“云原生推理基础设施”——这与 DaoCloud 深耕云原生领域、赋能 AI 规模化落地的核心方向完全一致。
Elastic EP 的核心价值,在于首次让 MoE 推理的四大核心要素,都具备了“运行时动态重构能力”:
- GPU 资源:按需动态调度,利用率最大化;
- 并行拓扑:实时调整,适配流量变化;
- 专家分布:动态均衡,保障推理效率;
- 通信组:灵活重构,支撑容错与弹性。
而这些能力,正是下一代 AI 基础设施的核心基础,能够支撑:
- 自动扩缩容:根据业务流量实时调整算力,无需人工干预;
- 故障恢复:全自动化故障处理,保障服务高可用;
- GPU 资源池化:实现算力共享,降低企业成本;
- 推理高可用:避免服务中断,保障 SLA 达标;
- 多租户共享:支持多个业务共享算力资源,提升资源利用率。
对于整个 MoE 推理生态而言,Elastic EP 是一个关键的演进方向——它解决了 MoE 模型规模化落地的核心痛点,让 MoE 推理从“实验室走向生产环境”,真正实现高效、稳定、低成本的部署。而 DaoCloud 作为云原生领域的领军企业,也将依托自身的云原生技术优势,推动 Elastic EP 等先进技术的落地,助力企业破解 AI 推理的算力难题,加速 AI 赋能实体经济的进程。
参考资料¶
- RFC #20323: Elastic Expert Parallelism
- PR #34861: [1/N] Elastic EP Milestone 2
- PR #35627: [2/N] Elastic EP Milestone 2: Integrating NIXL-EP
- RFC #30112: Fault-Tolerant Expert Parallelism
- RFC #16037: Data Parallel Attention and Expert Parallel MoEs
- 中国信通院《大模型推理优化关键技术及应用实践研究报告(2026年)》