产品架构¶
多云编排的管理面主要负责以下功能:
- 多云实例(基于 Karmada)的生命周期管理(LCM)
- 作为多云产品统一的流量入口(OpenAPI、Kairship UI、内部模块 GRPC 调用)
- 代理多云实例的 API 请求(Karmada 原生风格)
- 多云实例内的集群信息(监控、管理、控制)等的聚合
- 多云工作负载等资源的管理和监控
- 后续可能的权限操作
核心组件¶
多云编排主要包括两个核心组件: kairship-apiserver 和 kairship-controller-manager 。
Kairship-apiserver¶
Kairship-apiserver 主要担负着多云编排所有流量的入口(OpenAPI、GRPC 等),也是所有 API 的统一入口。 protobuf API 优先级最高,通过 proto 定义所有的 API 接口,并以此生成对应的前后端代码,使用 grpw-gateway 同时支持 HTTP Restful 和 GRPC。
启动的时候会从全局管理模块获取操作人的身份信息,用于后续 AuthZ 的安全性校验。
kairship-controller-manager¶
这是多云编排控制器,主要负责实例状态同步、资源搜集、Karmada 实例注册、全局资源注册等。
在多副本部署情况下,通过 leader 机制选举,保持同一个时刻只有一个工作的 Pod(参考 Kubernetes 的 controller-manager 选举机制)。
该组件主要负责多云编排一系列控制逻辑的处理(每个逻辑单独成 controller),通过 list-watch 机制监听特定对象的变更,然后处理对应事件。主要包括:
-
virtual-cluster-sync-controller
多云编排实例 CRD 的 CRUD 事件监听,一旦创建多云编排实例,则同步创建对应的虚拟集群管理资源。
多云编排实例所有资源的检索(多云工作负载、pp、op)都将通过容器管理模块内部的加速机制完成(借助 Clusterpedia),实现读写分离,进而提高性能。
实例删除,则同步删除注册在容器管理模块中的 virtual cluster。
-
resource statistics controller
主要搜集多云编排实例中加入的所有集群的统计信息,并将其回写到多云编排实例 CRD 中(例如该实例所管理的集群中总共包含多少 CPU、内存、节点数)。
-
status sync controller
多云编排实例本身的状态同步、统计。
-
instance registry controller
多云编排需要通过自定义资源将平台内所有 Karmada 实例注册到全局管理模块,这样才能在全局管理中完成角色与 Karmada 实例的绑定关系。 最终这些绑定关系会同步到多云编排模块中。
-
Ghippo webhook controller
在全局管理模块完成角色与 Karmada 实例的绑定关系之后,通过 sdk 告知多云编排,多云编排据此完成鉴权动作。
数据流图¶
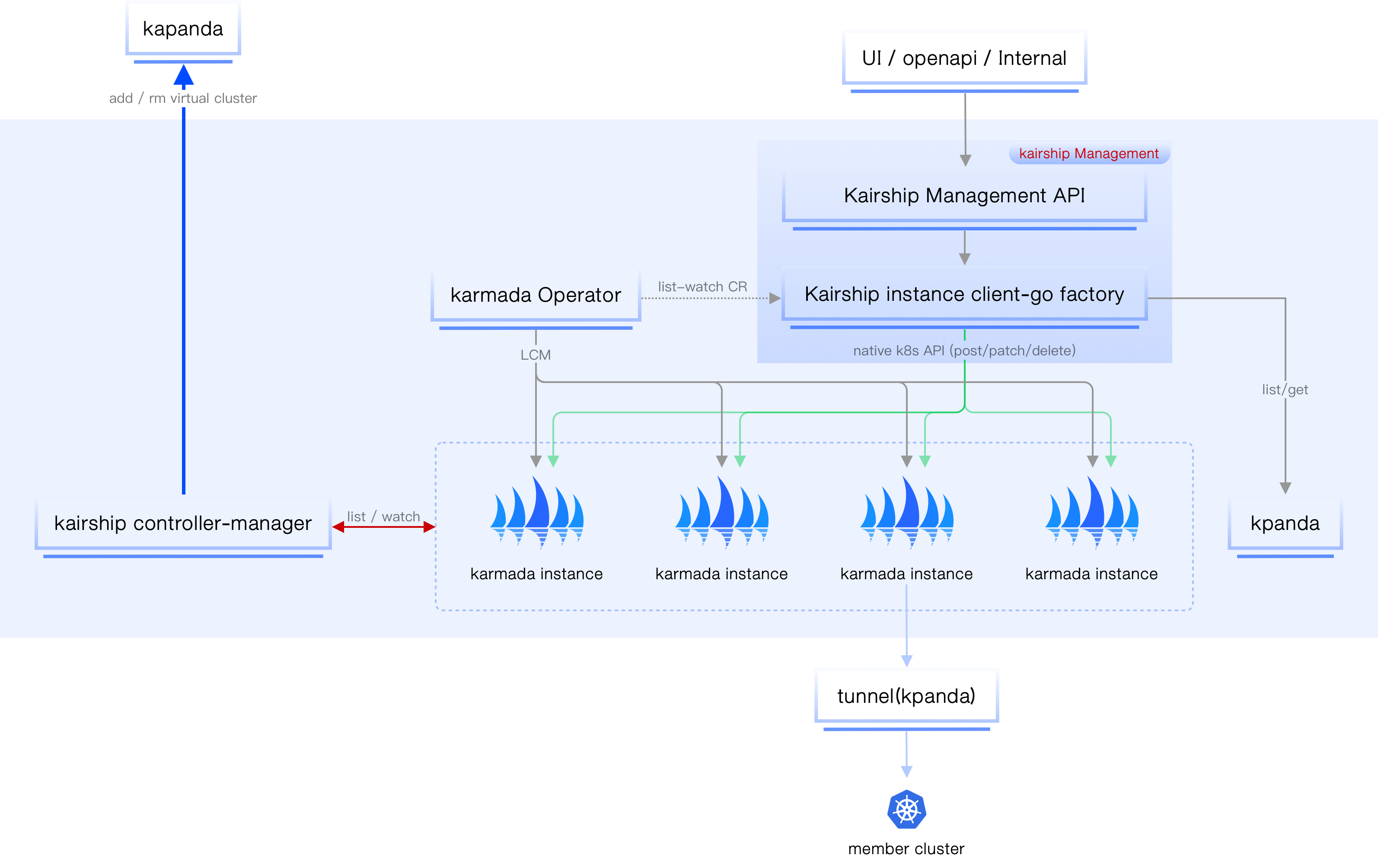
首先需要说明的是,多云实例之间互不感知、相互隔离。
多云编排管理:
- 获取 Karmada 相关的分发策略以及应用的状态信息。
- 获取多云编排实例内的集群、节点的统计、监控信息。
- 编辑、更新、删除相关 Karmada 实例中的多云应用相关的信息(主要围绕 Karmada 工作负载和 pp、op 两个 CRD)。
所有的请求数据流都直接传递到位于全局服务集群的多云编排实例中。
接着,所有访问请求经过多云编排之后将会被分流到对应的实例中。所有 get/list 之类的读请求将会访问容器管理模块,写请求会访问 Karmada 实例,这样可以做到读写分离,加快响应时间。
您可能好奇容器管理模块如何获取多云编排实例的相关资源信息?方法就是,把实例本身作为一个虚拟集群加入到容器管理模块中(不在容器管理中显示)。这样就可以完全借助容器管理模块的能力(搜集加速检索各个 Kubernetes 集群的资源、CRD 等),当在界面中查询某个多云编排实例的资源(Deployment、部署策略、差异化策略等)就可以直接通过容器管理模块进行检索。