Kafka + Elasticsearch 流式架构应对超大规模日志方案¶
随着业务发展,越来越多的应用产生的日志数据会越来越多,为了保证系统能够正常采集并分析庞杂的日志数据时, 一般做法是引入 Kafka 的流式架构来解决大量数据异步采集的方案。采集到的日志数据会经过 Kafka 流转, 由相应的数据消费组件将数据从 Kafka 消费存入到 Elasticsearch 中,并通过 Insight 进行可视化展示与分析。
本文将介绍以下两种方案:
- Fluentbit + Kafka + Logstash + Elasticsearch
- Fluentbit + Kafka + Vector + Elasticsearch
当我们在日志系统中引入 Kafka 之后,数据流图如下图所示:
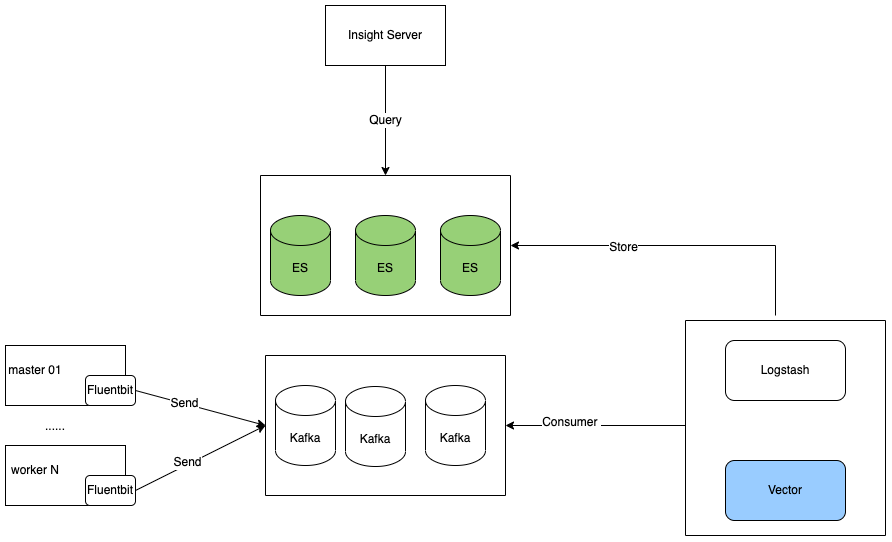
上面两种方案中有共通的地方,不同之处在于消费 Kafka 数据的组件,同时,为了不影响 Insight 数据分析, 我们需要在消费 Kafka 数据并写入到 ES 的数据和原来 Fluentbit 直接写入 ES 的数据的格式一致。
首先我们来看看 Fluentbit 怎么将日志写入 Kafka:
修改 Fluentbit Output 配置¶
当 Kafka 集群准备就绪之后,我们需要修改 insight-system 命名空间下 ConfigMap 的内容, 新增以下三个 Kafka Output 并注释原来三个 Elasticsearch Output:
假设 Kafka Brokers 地址为: insight-kafka.insight-system.svc.cluster.local:9092
[OUTPUT]
Name kafka
Match_Regex (?:kube|syslog)\.(.*)
Brokers insight-kafka.insight-system.svc.cluster.local:9092
Topics insight-logs
format json
timestamp_key @timestamp
rdkafka.batch.size 65536
rdkafka.compression.level 6
rdkafka.compression.type lz4
rdkafka.linger.ms 0
rdkafka.log.connection.close false
rdkafka.message.max.bytes 2.097152e+06
rdkafka.request.required.acks 1
[OUTPUT]
Name kafka
Match_Regex (?:skoala-gw)\.(.*)
Brokers insight-kafka.insight-system.svc.cluster.local:9092
Topics insight-gw-skoala
format json
timestamp_key @timestamp
rdkafka.batch.size 65536
rdkafka.compression.level 6
rdkafka.compression.type lz4
rdkafka.linger.ms 0
rdkafka.log.connection.close false
rdkafka.message.max.bytes 2.097152e+06
rdkafka.request.required.acks 1
[OUTPUT]
Name kafka
Match_Regex (?:kubeevent)\.(.*)
Brokers insight-kafka.insight-system.svc.cluster.local:9092
Topics insight-event
format json
timestamp_key @timestamp
rdkafka.batch.size 65536
rdkafka.compression.level 6
rdkafka.compression.type lz4
rdkafka.linger.ms 0
rdkafka.log.connection.close false
rdkafka.message.max.bytes 2.097152e+06
rdkafka.request.required.acks 1
接下来就是消费 Kafka 数据之后写到 ES 的细微差别。 正如本文开始的描述,本文将介绍 Logstash 与 Vector 作为消费 Kafka 的两种方式。
消费 Kafka 并写入 Elasticsearch¶
假设 Elasticsearch 的地址为:https://mcamel-common-es-cluster-es-http.mcamel-system:9200
通过 Logstash 消费¶
如果你对 Logstash 技术栈比较熟悉,你可以继续使用该方式。
当你通过 Helm 部署 Logstash 的时候, 在 logstashPipeline 中增加如下 Pipeline 即可:
replicas: 3
resources:
requests:
cpu: 100m
memory: 1536Mi
limits:
cpu: 1000m
memory: 1536Mi
logstashConfig:
logstash.yml: |
http.host: 0.0.0.0
xpack.monitoring.enabled: false
logstashPipeline:
insight-event.conf: |
input {
kafka {
add_field => {"kafka_topic" => "insight-event"}
topics => ["insight-event"]
bootstrap_servers => "172.30.120.189:32082" # kafka的ip 和端口
enable_auto_commit => true
consumer_threads => 1 # 对应 partition 的数量
decorate_events => true
codec => "plain"
}
}
filter {
mutate { gsub => [ "message", "@timestamp", "_@timestamp"] }
json {source => "message"}
date {
match => [ "_@timestamp", "UNIX" ]
remove_field => "_@timestamp"
remove_tag => "_timestampparsefailure"
}
mutate {
remove_field => ["event", "message"]
}
}
output {
if [kafka_topic] == "insight-event" {
elasticsearch {
hosts => ["https://172.30.120.201:32427"] # elasticsearch 地址
user => 'elastic' # elasticsearch 用户名
ssl => 'true'
password => '0OWj4D54GTH3xK06f9Gg01Zk' # elasticsearch 密码
ssl_certificate_verification => 'false'
action => "create"
index => "insight-es-k8s-event-logs-alias"
data_stream => "false"
}
}
}
insight-gw-skoala.conf: |
input {
kafka {
add_field => {"kafka_topic" => "insight-gw-skoala"}
topics => ["insight-gw-skoala"]
bootstrap_servers => "172.30.120.189:32082"
enable_auto_commit => true
consumer_threads => 1
decorate_events => true
codec => "plain"
}
}
filter {
mutate { gsub => [ "message", "@timestamp", "_@timestamp"] }
json {source => "message"}
date {
match => [ "_@timestamp", "UNIX" ]
remove_field => "_@timestamp"
remove_tag => "_timestampparsefailure"
}
mutate {
remove_field => ["event", "message"]
}
}
output {
if [kafka_topic] == "insight-gw-skoala" {
elasticsearch {
hosts => ["https://172.30.120.201:32427"]
user => 'elastic'
ssl => 'true'
password => '0OWj4D54GTH3xK06f9Gg01Zk'
ssl_certificate_verification => 'false'
action => "create"
index => "skoala-gw-alias"
data_stream => "false"
}
}
}
insight-logs.conf: |
input {
kafka {
add_field => {"kafka_topic" => "insight-logs"}
topics => ["insight-logs"]
bootstrap_servers => "172.30.120.189:32082"
enable_auto_commit => true
consumer_threads => 1
decorate_events => true
codec => "plain"
}
}
filter {
mutate { gsub => [ "message", "@timestamp", "_@timestamp"] }
json {source => "message"}
date {
match => [ "_@timestamp", "UNIX" ]
remove_field => "_@timestamp"
remove_tag => "_timestampparsefailure"
}
mutate {
remove_field => ["event", "message"]
}
}
output {
if [kafka_topic] == "insight-logs" {
elasticsearch {
hosts => ["https://172.30.120.201:32427"]
user => 'elastic'
ssl => 'true'
password => '0OWj4D54GTH3xK06f9Gg01Zk'
ssl_certificate_verification => 'false'
action => "create"
index => "insight-es-k8s-logs-alias"
data_stream => "false"
}
}
}
通过 Vector 消费¶
如果你对 Vector 技术栈比较熟悉,你可以继续使用该方式。
当你通过 Helm 部署 Vector 的时候,引用如下规则的 Configmap 配置文件即可:
metadata:
name: vector
apiVersion: v1
data:
aggregator.yaml: |
api:
enabled: true
address: '0.0.0.0:8686'
sources:
insight_logs_kafka:
type: kafka
bootstrap_servers: 'insight-kafka.insight-system.svc.cluster.local:9092'
group_id: consumer-group-insight
topics:
- insight-logs
insight_event_kafka:
type: kafka
bootstrap_servers: 'insight-kafka.insight-system.svc.cluster.local:9092'
group_id: consumer-group-insight
topics:
- insight-event
insight_gw_skoala_kafka:
type: kafka
bootstrap_servers: 'insight-kafka.insight-system.svc.cluster.local:9092'
group_id: consumer-group-insight
topics:
- insight-gw-skoala
transforms:
insight_logs_remap:
type: remap
inputs:
- insight_logs_kafka
source: |2
. = parse_json!(string!(.message))
.@timestamp = now()
insight_event_kafka_remap:
type: remap
inputs:
- insight_event_kafka
- insight_gw_skoala_kafka
source: |2
. = parse_json!(string!(.message))
.@timestamp = now()
insight_gw_skoala_kafka_remap:
type: remap
inputs:
- insight_gw_skoala_kafka
source: |2
. = parse_json!(string!(.message))
.@timestamp = now()
sinks:
insight_es_logs:
type: elasticsearch
inputs:
- insight_logs_remap
api_version: auto
auth:
strategy: basic
user: elastic
password: 8QZJ656ax3TXZqQh205l3Ee0
bulk:
index: insight-es-k8s-logs-alias-1418
endpoints:
- 'https://mcamel-common-es-cluster-es-http.mcamel-system:9200'
tls:
verify_certificate: false
verify_hostname: false
insight_es_event:
type: elasticsearch
inputs:
- insight_event_kafka_remap
api_version: auto
auth:
strategy: basic
user: elastic
password: 8QZJ656ax3TXZqQh205l3Ee0
bulk:
index: insight-es-k8s-event-logs-alias-1418
endpoints:
- 'https://mcamel-common-es-cluster-es-http.mcamel-system:9200'
tls:
verify_certificate: false
verify_hostname: false
insight_es_gw_skoala:
type: elasticsearch
inputs:
- insight_gw_skoala_kafka_remap
api_version: auto
auth:
strategy: basic
user: elastic
password: 8QZJ656ax3TXZqQh205l3Ee0
bulk:
index: skoala-gw-alias-1418
endpoints:
- 'https://mcamel-common-es-cluster-es-http.mcamel-system:9200'
tls:
verify_certificate: false
verify_hostname: false
检查是否正常工作¶
你可以通过查看 Insight 日志查询界面是否有最新的数据,或者查看原本 Elasticsearch 的索引的数量有没有增长,增长即代表配置成功。